
Last updated on 7. Mai 2020
0. Inhaltsverzeichnis – Teil 2 Softwae
- Grundüberlegungen zur Server-Software
- Start mit dem AMI-BIOS
- Das BIOS des Adaptec-RAID-Controllers
- Ubuntu-Server installieren
- Den RAID-Controller und das RAID einrichten
- Samba Server Datenaustausch mit dem „smb-Protokoll“
- Sicherheitsmaßnahmen für Samba und SSH
- sFTP-Server mit openSSH-Server realisieren/teilweise
- Netzwerk von DHCP auf feste IP-Adresse umstellen, LAN-Leitungen bündeln
- Verschicken von Statusmeldungen per Mail
- Ungelöste Probleme
- Abschließende Betrachtungen
I. Grundüberlegungen zur Server-Software
Der Fileserver sollte schnell, einfach und sicher sein. Damit scheiden Produkte wie Windows Server von vorneherein aus und es bleibt eigentlich nur Linux. Bei Linux hat man die Wahl zwischen verschiedenen Distributionen (Wikipedia Linux Distributionen) und unter den Distributionen wiederum verschiedene „Flavours“, also Abwandlungen, die den „Geschmack“ einer bestimmten Benutzergruppe treffen.
Linux bezeichnet eigentlich nur den Kern des Betriebssystems, die Distributionen fügen das restliche Umfeld hinzu. Die deutsche „Linux-Bibel“ stammt von Michael Kofler („Der Kofler“) und ist gut verständlich geschrieben: Linux – Das umfassende Handbuch
Anmerkung: Als mündige Bürger sollten wir natürlich nicht beim großen Haifisch Amazon bestellen, sondern bei einer kleineren Plattform oder im Fachhandel.
Die am besten, für jemandem, der sich nicht täglich mit Linux beschäftigt, dokumentierte Distribution ist Ubuntu der südafrikanischen Firma Canonical. Es gibt einen einfachen Update-Mechanismus und eine sehr gute Community (sogar auf Deutsch), die bei Problemen und Fragen hilft Lösungen zu finden: https://ubuntuusers.de/
Der Nachteil bei Ubuntu ist, dass man nicht immer so genau weiß, was die Firma Canonical hinter verschlossenen Türen so alles treibt. Da es sich um Open-Source handelt kann man natürlich zumindest theoretisch (viele Linux-Helden tun das) den ganzen Programmcode durchsehen, dennoch hat sich Canonical z. B. mit der Übermittlung von Daten an Amazon (bei der Suche in der Desktop-Version) nicht gerade Freunde gemacht. (So werden sie die Amazon-Suche wieder los.)
Bei Open-Source-Software muss in der Regel alles was dazukommt ebenfalls wieder Open-Source sein. Dies ist manchmal sehr schwierig, wenn man z. B. einen Druckertreiber eines speziellen Druckers verwenden will, der z. B. von HP kommt. Verwendet man das „main-Package“ kommt man aber in der Regel ohne Erweiterungen klar, es sei denn, man hat ganz spezielle Grafikkarten oder ähnliches installiert. Beim Server ist es sowieso einfacher da man sich um Grafik, Drucker und Monitore keine Sorgen machen muss. Es ist zwar manchmal nicht schlecht mit Tastatur, Maus und Monitor direkt am Server zu arbeiten, aber dafür reichen die billigsten Standardgeräte aus, da man sie sowieso nur ganz selten braucht.
Es gibt bei Linux zwei wichtige Hauptfamilien, die jeweils auch eigene Software-Pakete auf eigenen Plattformen anbieten: einmal die Debian-Familie, zu der auch Ubuntu gehört (Debian-GNU/Linux-Derivat) mit dem DEB Packetmanager und die Fedora-Red Hat-SUSE Familie mit dem RPM Package Manager. Das Installieren von Software funktioniert jeweils mit etwas anderen Befehlen: „dnf“, „yum“, „zypper“ bei RPM und „apt-get“ bei Debian/Ubuntu.
Da meine Lebenszeit beschränkt ist und ich nicht die freie Zeit habe mich in etwas speziellere Linux-Distributionen einzuarbeiten (obwohl ich es natürlich gerne täte) habe ich mich für Ubuntu-Server entschieden.
Ubuntu Server
Es gibt Long-Term-Support LTS Versionen, die über fünf Jahre von Ubuntu eine Updategarantie bekommen. Dann gibt es neuere Versionen, die noch teileweise im Entwicklungsstadium sind. Für einen Server eignet sich eine LTS-Version, nur falls man Spam-Filter verwendet sollten diese natürlich immer am Puls der Zeit sein. Die LTS-Versionen werden mit dem Jahr und dem Monat der ersten Veröffentlichung bezeichnet. Bei mir ist dies Ubuntu 16.10 LTS mit dem Beinahmen „Yakkety Yak“.
Der Server bekommt folgende Hauptprogramme bzw. Dienste:
a. SSH-Server (verschlüsselte Fernwartung/Installation incl. secure-FTP)
b. Samba-Fileserver (Dateiaustausch)
c. Mail-Server (minimal, nur um Warnmeldungen zu senden)
Standardanforderungen an die Hardware für einen Ubuntu Server
1 GHz Prozessor
512 MB Arbeitsspeicher
1 GB Festplatte
Was hat unser Server an technischer Ausstattung
(siehe Hardware Teil)
Supermicro Mainboard mit 1,9 GHz, 6 Kernen und 12 Threads
integrierter Grafikprozessor
32 GB Arbeitsspeicher
120 GB SSD-Festplatte für das System
48 TB SATA-Festplatten für Daten am Raid-Controller im PCIe 3.0 Steckplatz
2 x 10 Gb/s LAN
1 x IPMI LAN
USB 3.0 und 2.0
VAG Port für einen Monitor
BIOS 128 Mb SPI Flash mit AMI BIOS
UEFI 2.4
Beim AMI-BIOS gibt es Legancy-, UEFI- und DUAL-Boot-Mode.
Für UEFI gibt es eine UEFI-Shell in der man direkt ins System mit Befehlen eingreifen kann. (Dies ist aber auch ein Sicherheitsrisiko.)
EFI (UEFI = Weiterentwicklung von Windows) ist ein neues BIOS-System, das es erlaubt mehr als 2 TByte auf einer Festplatte zu verwalten und die Festplatten mit einer modernen GUID Partition Table (GPT) zu versehen. (Bei Windows ab Version 8 im Einsatz, beim Mac schon längere Zeit.) Da Linux GPT von Hause aus schon lange kann, kann man auch mit dem BIOS arbeiten. Zeitgemäßer ist jedoch UEFI, das aber eine 64-Bit-Version von Linux braucht und bei Ubuntu ab 12.10 in vollem Umgang funktioniert.
Das Mainboard ist laut Supermicro Internetseite für den Betrieb mit Ubuntu 14.10 LTS und 15.10 geeignet und getestet. Ob es mit 16.10 LTS läuft muss man also selbst testen. Bei mir hat es funktioniert.
II. Start mit dem AMI-BIOS
Ein Windows-Keyboard (mit Funktionstasten) und einen Monitor mit VGA-Kabel braucht man um direkt am Server zu arbeiten.
Schaltet man den Server ein, so meldet sich zuerst das AMI-BIOS des Mainboards und im Laufe des Startprozesse auch das BIOS des Raid-Controllers. Beide Prozesse kann man anhalten, um im jeweiligen System Einstellungen vorzunehmen.
Anhalten AMI-BIOS: F11 oder DELETE
Anhalten Raid-Controller BIOS: CTRL+A
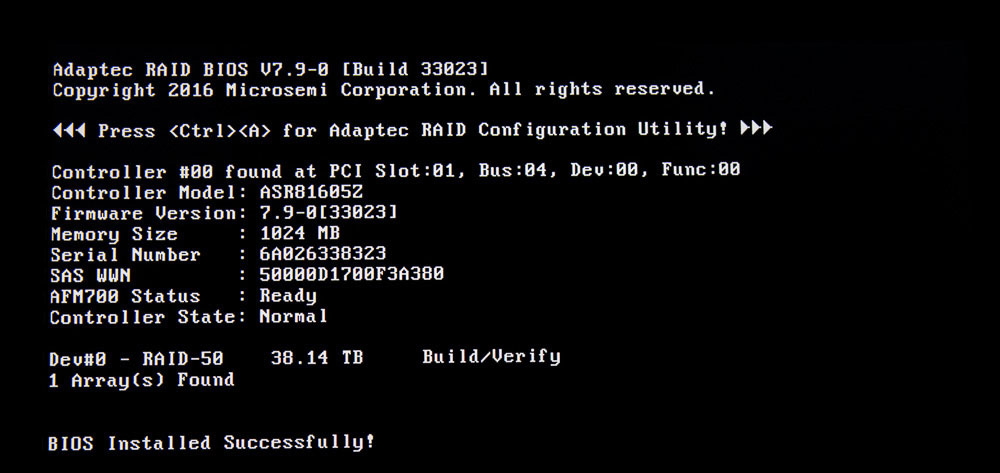
An Anfang des AMI-BIOS-Starts startet zuerst das Raid-Controller-BIOS. Hier noch mit einer RAID-50-Einstellung, die ich getestet habe. Man kann von hier aus ein ganzes Raid-System einrichten. Weiter unten dazu mehr. Will man Einstellungen vornehmen muss man „Ctrl-a“ drücken.

Wenn das AMI-BIOS startet, hat man ein paar Sekunden Zeit, alles zu lesen und noch rechtzeitig die F11-Taste zu drücken, damit man zu den Einstellungen kommt.
AMI-BIOS
Den RAID-Controller lassen wir momentan wie er ist und widmen uns dem AMI-BIOS des Mainboards.

AMI-BIOS Startauswahl.
Im Startmenü hat man mehrere Möglichkeiten. Wichtig ist: „Enter Setup„, man erreicht den Eintrag mit den Pfeiltasten auf der Tastatur und mit „Enter“. Die Maus funktioniert hier nicht, falls man eine solche angeschlossen hat!
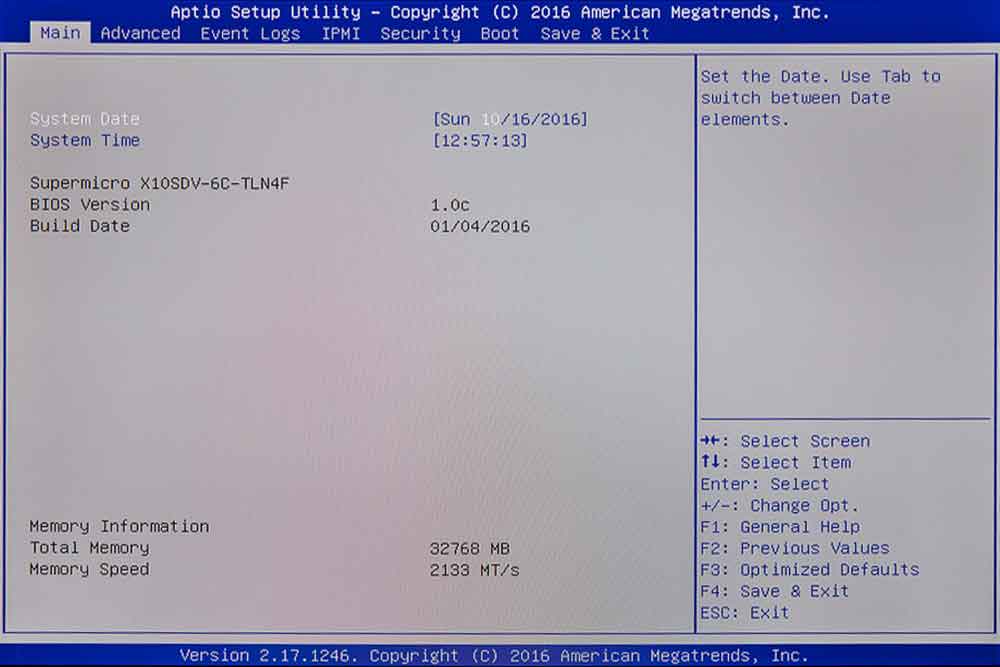
BIOS Main Setup ist die Startseite, von hier aus gelangt man in die anderen Menüs. Man sieht hier ob die Uhrzeit über das LAN richtig ankommt (Zeitserver im Router) und ob der RAM-Speicher in vollem Umfang erkannt wurde (unten links).
Unsere erste Aufgabe ist es dem BIOS mitzuteilen, dass wir für das System eine SSD verwenden. Dies geschieht unter „Advanced“.
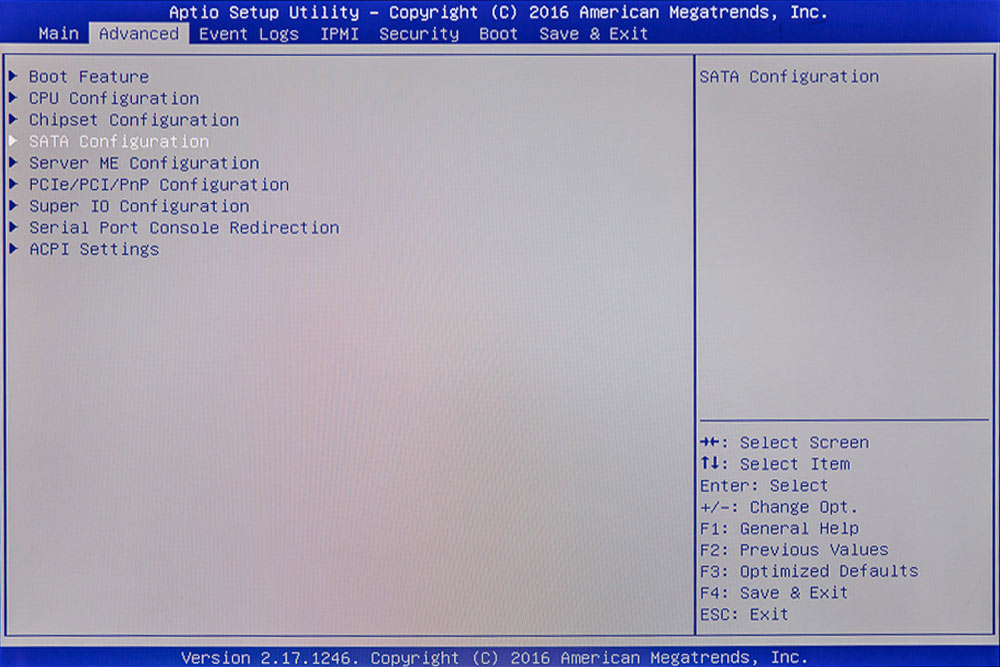
BIOS „Advanced“. Unter „SATA Configuration“ verbirgt sich natürlich das Festplattenmenü.
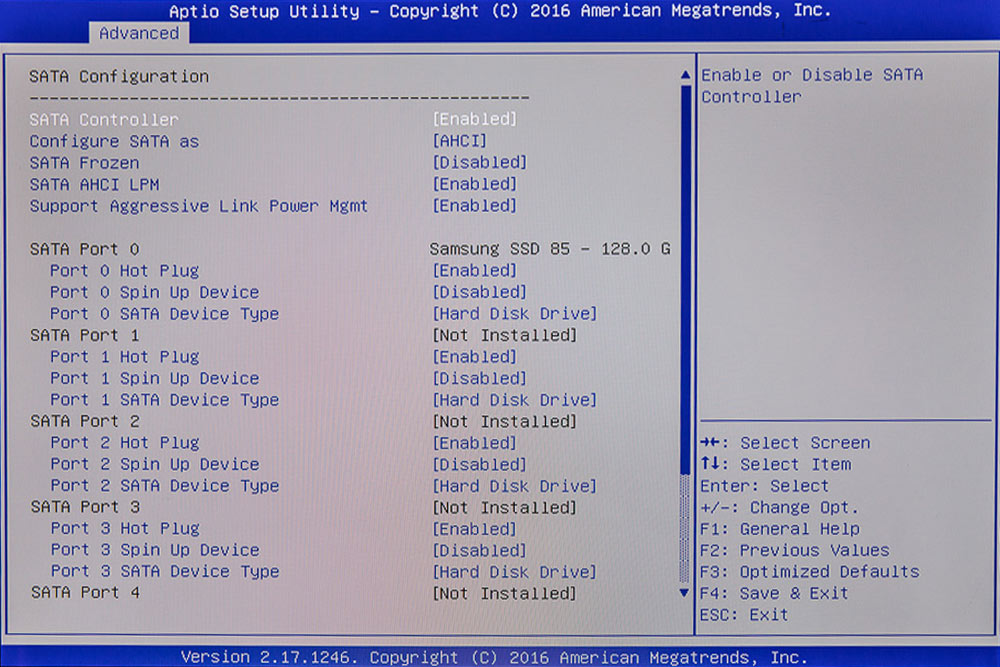
SATA-Konfiguration im BIOS. Unter „SATA Port 0 / SATA Device Type ist noch [Hard Disk Drive] eingestellt. Mit den Pfeiltasten und „Enter“ kommen wir zum Menü und können auf SSD/Solid State Drive umstellen.
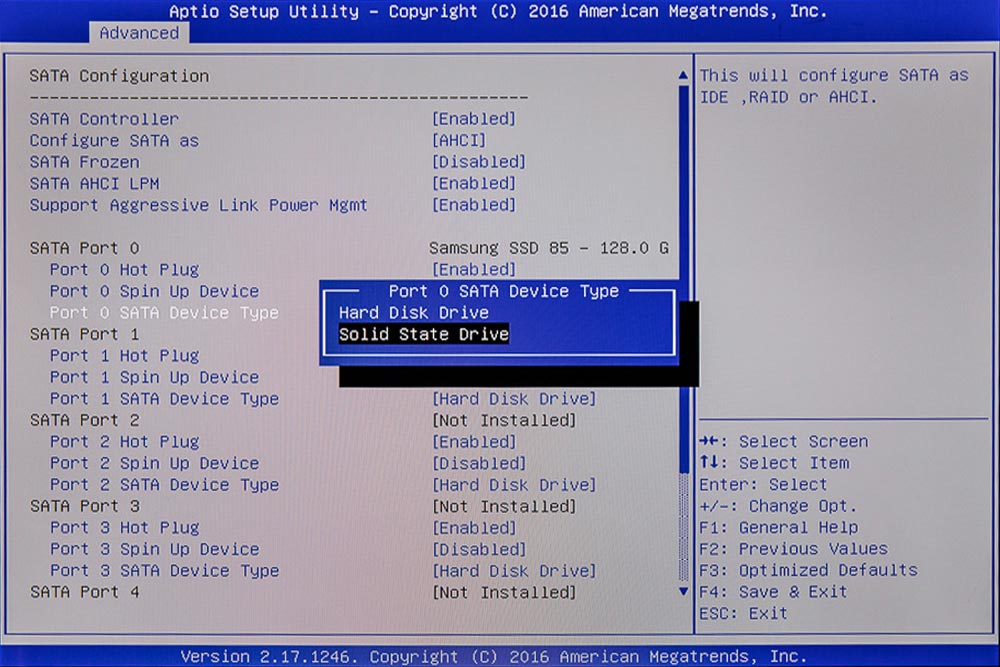
Im AMI-BIOS SSD einstellen. Beim Verlassen des BIOS muss das Ganze dann gespeichert werden!
Zweite Aufgabe im BIOS: IPMI einrichten
Intelligent Platform Management Interface (IPMI) ist eine Schnittstelle, über die man den Rechner überwachen und warten kann. Es gibt Daten zur Temperatur, zum Speicher, zu den Lüftern und alles Mögliche, was sich so auf dem Mainboard tut. Dafür gibt es eine eigene IPMI-LAN-Buchse über die man einfach ein LAN-Kabel auf den Switch legt. Um den Zugang zu erleichtern sollte man, genauso wie beim normalen Server-LAN auch IPMI eine feste IP-Adresse geben. Dies macht man im Router und trägt die gewählte Adresse dann hier ein. Es funktioniert aber auch mit einer dynamischen automatischen Zuweisung über DHCP.
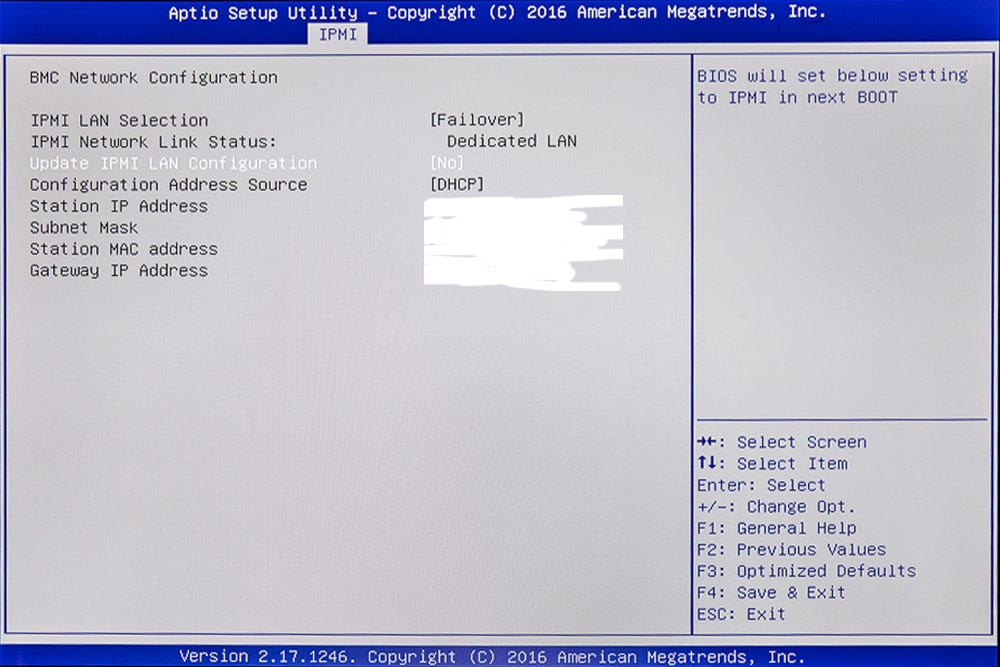
IPMI IP-Adresse einstellen. Dazu braucht man noch einen „user name“ und ein „password“.
IPMI Default Passwort und User-Name Einstellungen sind: ADMIN und ADMIN.
Die sollten natürlich später auf alle Fälle ausgetauscht werden. Der Passwortwechsel funktioniert über das IPMI-Menü, nicht hier im BIOS.
Achtung:
Wenn man innerhalb des IPMI-Tools das Passwort unter „Configuration-Users“ für eine Benutzer ändert und das Passwort zu lang ist (> 20 Byte) dann wird es zwar angenommen und auch mit „Passwort geändert“ quittiert, nur kommt man dann beim Einloggen nicht mehr in das IPMI-Menü. Die Lösung darin besteht, das Passwort mit dem Linux-Programm „ipmitool“ wieder zu ändern. Passwort Probleme bei komplizierten SMPT-Mail-Passwörtern gibt es mit IPMI auch wenn man später die Mail-Benachrichtung einrichtet (siehe weiter unten).
Mit dem „ipmitool“ kann man das Passwort für den IPMI-Zugang ändern. Alternativ kann man IPMI auch ganz abstellen, wenn der Server mal läuft.
Zum ändern des Passwortes bei IPMI und zu Sicherheitsaspekten bei IPMI gibt es gute Beiträge von Thomas Krenn.
BIOS-Setup mit einem Passwort sichern
Wer einen Tor-Exit-Node betreibt und deshalb, wenn er im Urlaub ist, immer Besuch von der NSA bekommt, der kann auch das ganze BIOS mit einem Passwort absichern.
ACHTUNG:
Der Server sollte nach einem Problem wieder alleine starten können und nicht an einer Passworteingabe hängen bleiben.
Hier kann man auch die Einstellungen zu „Secure Boot“ vornehmen: siehe weiter unten bei UEFI. Ich habe „Secure Boot“ auf „disabled“ gelassen.
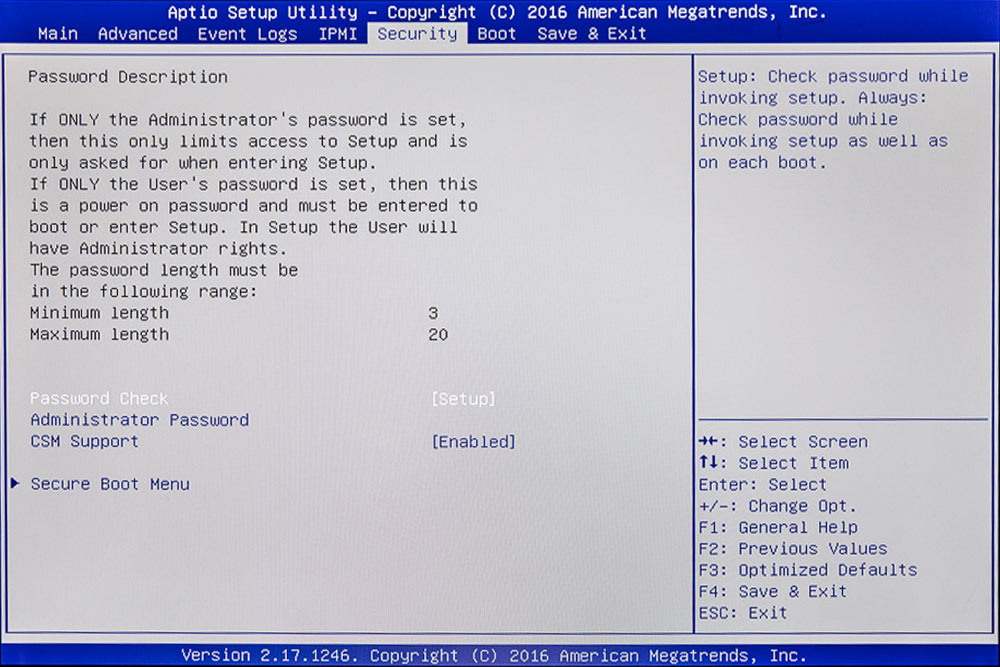
BIOS mit einem Passwort absichern.
Von AMI-BIOS auf UEFI umstellen
Das „U“ bei UEFI steht für „unified“. Windows hat das EFI-System weiterentwickelt um die Sicherheitskomponente „Secure Boot“. Dies bedeutet, dass der Kernel nur startet, wenn auf dem Mainboard die entsprechenden Schlüssel hinterlegt sind. Damit kann man verhindern, dass schon beim booten Spionage- und Schadsoftware geladen wird. Leider haben die Boards in der Regel nur den Windows-Schlüssel hinterlegt. Die Distributionen müssen diesen bei Microsoft kaufen, damit sie ihn verwenden dürfen. Deshalb wird bei Linux diese Funktion meist nicht genutzt, obwohl Ubuntu den Windows-Schlüssel wohl gekauft hat und mit dem Windows-Schlüssel den Linux-Kernel starten kann.
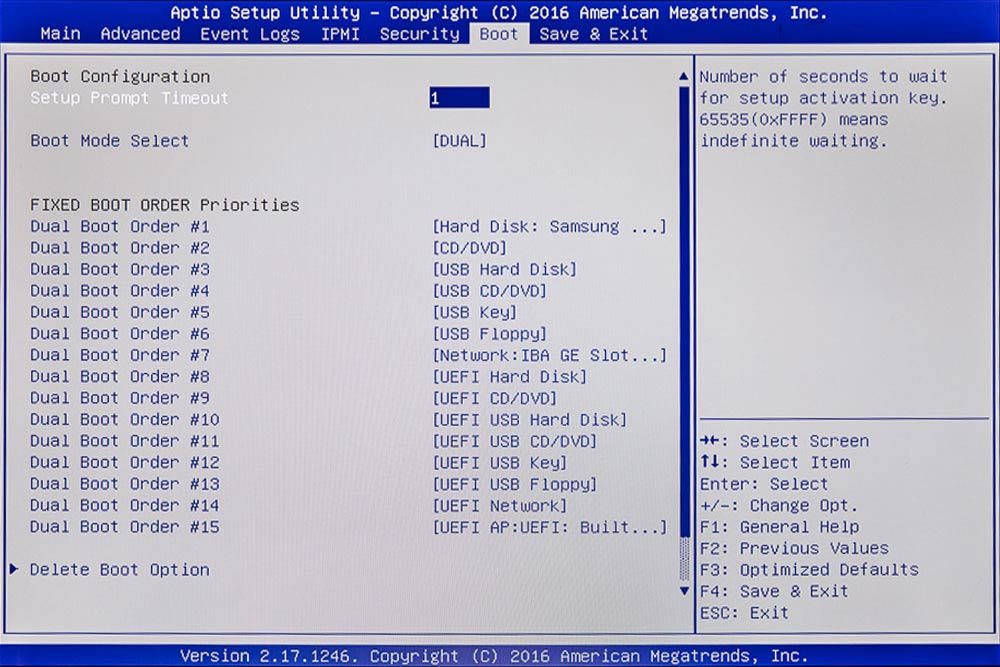
Hier ist noch ein „DUAL-Boot-Mode“ eingestellt, was bedeutet, dass zuerst versucht wird im „EFI-Modus“ zu booten und falls dies misslingt versucht es der Treiber im „BIOS-Modus“.
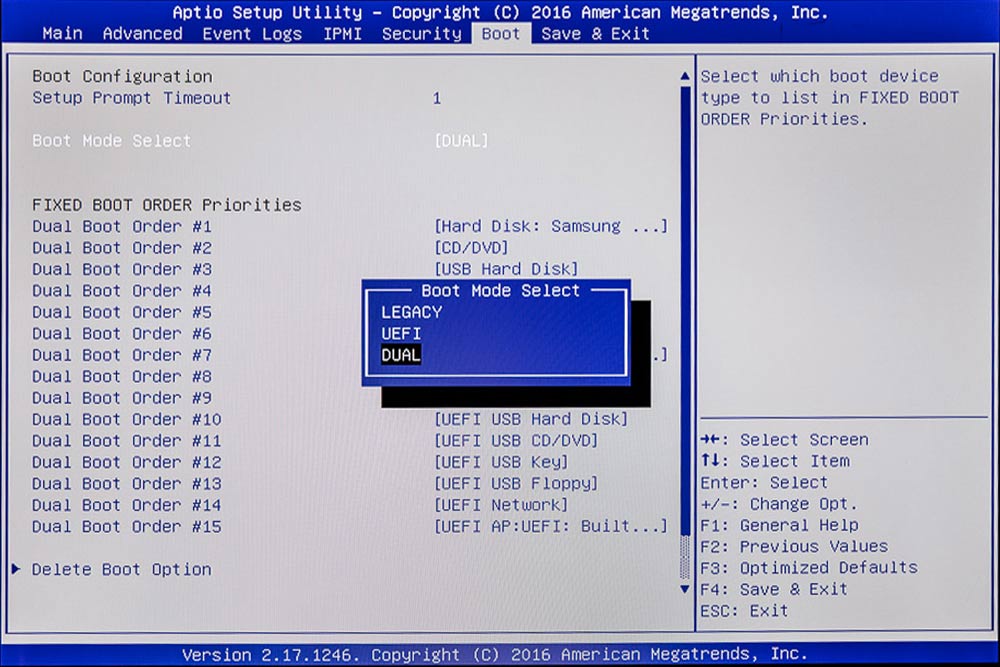
Umschalten auf UEFI, damit Ubuntu auch tatsächlich den EFI-Modus anwendet.
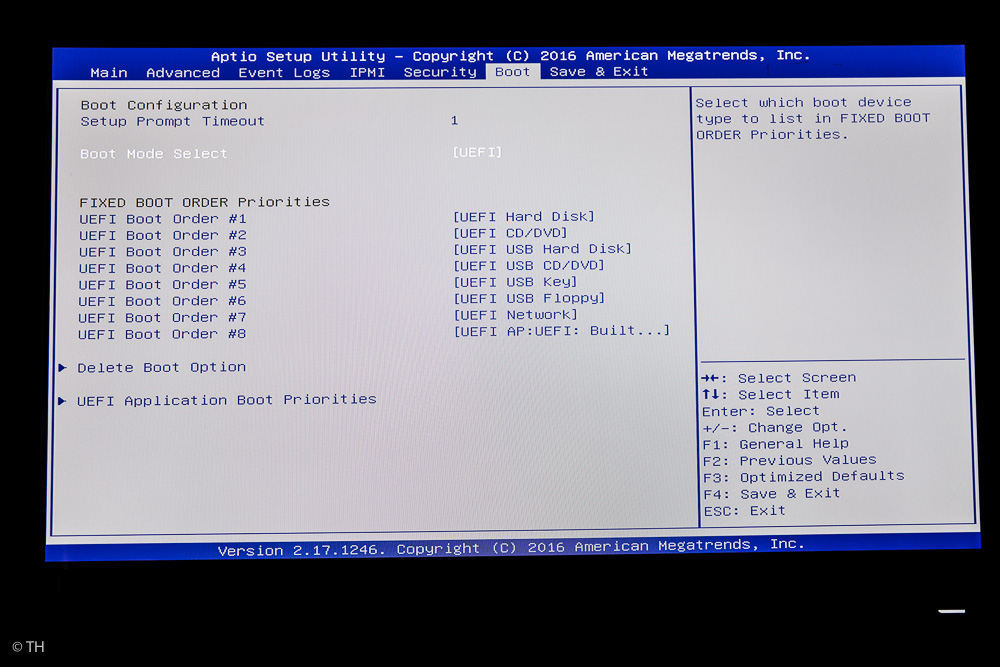
UEFI Boot Mode
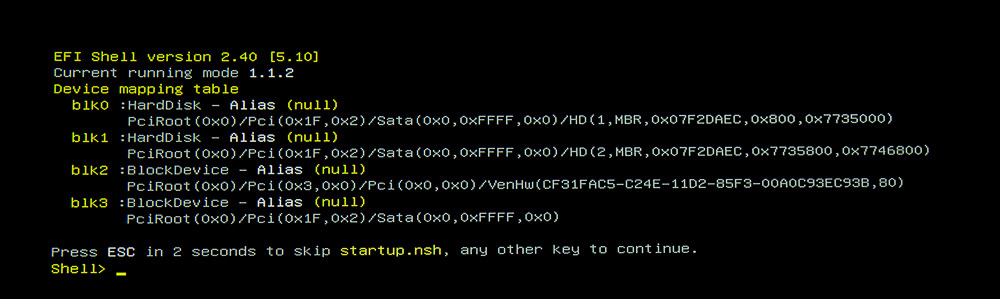
EFI-Schell für ganz spezielle Einstellungen, falls diese nötig sind. Sie erscheint auch, wenn es irgendwo hakt oder etwas nicht ganz stimmt, automatisch. Hier hat der „EFI-BOOT“ nicht funktioniert, da er noch gar nicht eingerichtet war.
Einen Überblick über die möglichen Befehle gibt es unter „help“ oder im Netz: EFI-Shell-Befehle
III. Das BIOS des Adaptec-Raid-Controllers
Zu erreichen über „CTRL+a“ beim Raid-Controller-BIOS-Start, innerhalb des normalen BIOS-Starts.
Laut Hersteller sollte das BIOS jedoch nicht zur Verwaltung des RAID-Controllers benutzt werden, sondern der maxView-Storage-Manger, eine spezielle Software für diesen Controller. Dazu weiter unten mehr, hier aber trotzdem das RAID-Controller-BIOS:
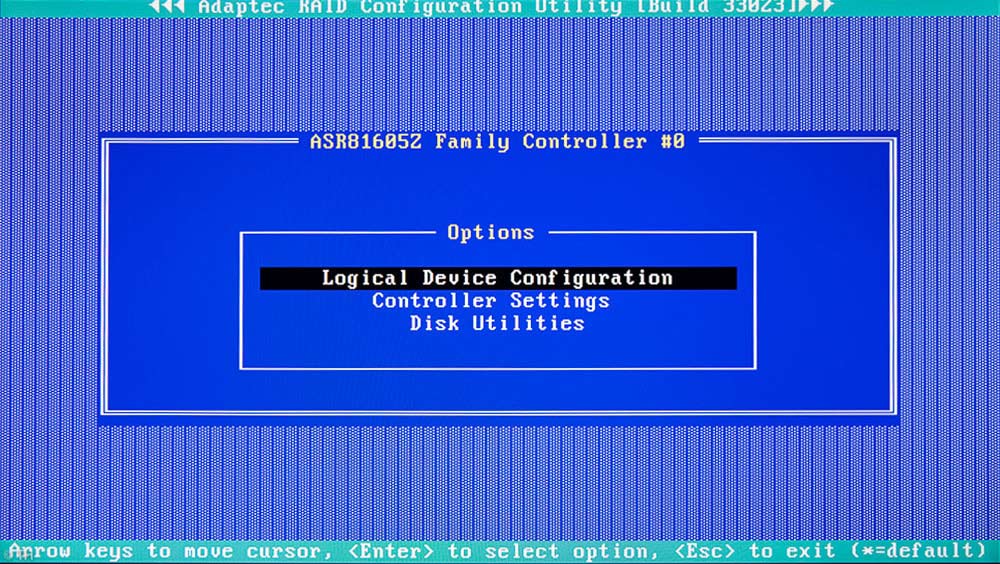
RAID-Controller-BIOS

RAID-Controller-Bios. Hier mein schon angelegter RAID 50 Test-Array. Darunter sieht man links das „Create-Array-Menü“.
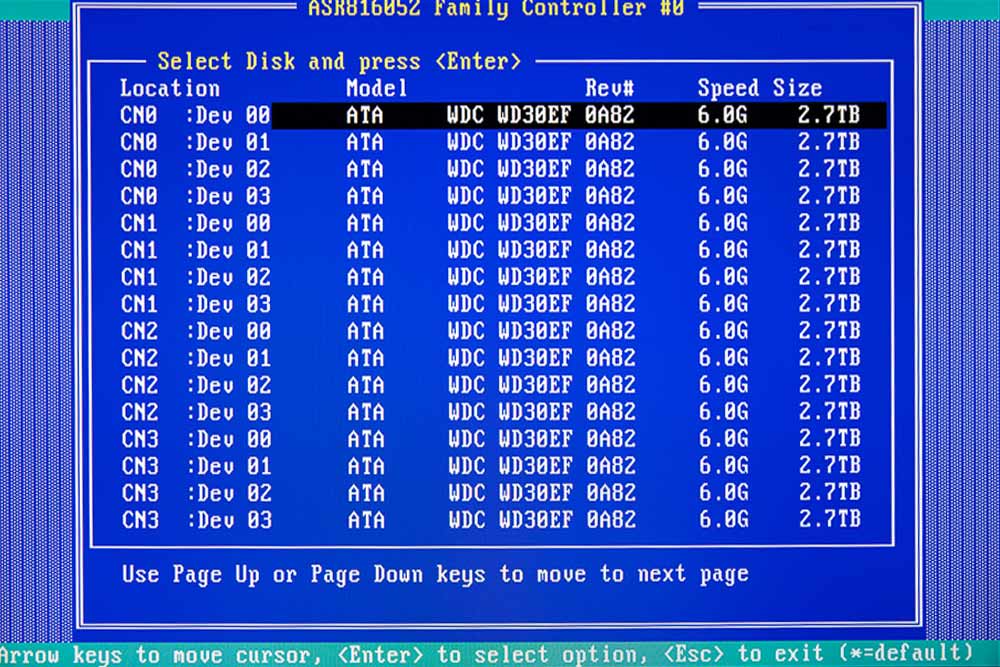
Einzelne Festplatten im RAID-Controller-BIOS und ihre Steckplätze. (Achtung: Die Bezeichnung der Kabelbuchsen (CNx) in der Bedienungsanleitung (welche Buchse ist wo auf dem Mainboard) ist falsch. Das kann man z. B. testen, indem man einzelne Platten abzieht oder mithilfe des maxView-Storage-Managers. Eine korrigierte Zeichnung findet man in „Teil 1– Hardware“, am Anfang.)
Über das RAID-Controller-BIOS kann man ein komplettes RAID anlegen, indem man einen Array bildet und den RAID-Level wählt. Alternativ – die einzig richtige Herangehensweise laut Hersteller – macht man dies über den maxView-Storage-Manager, einer Software, die auf dem Server installiert werden muss und die über LAN dann das komplette RAID verwaltet.
Alte Systemsoftware beim RAID-Controller
Bei mir war das Problem, dass im BIOS plötzlich Bezeichnungen waren wie „BOX00 :02“ oder „EXP0 : phy0“ oder einzelne Festplattenplätze „CNX : DEV XX“ doppelt vorkamen. Es wurden „Backplane-Anschlüsse“ und „Expander-Anschlüsse“ angezeigt, die es nicht gab. Alle meine Festplatten sind direkt und nicht über eine Backplane angeschlossen.
Der Servershop-Bayern hatte, als ich um Rat fragte, gleich die Vermutung, dass die Systemsoftware des RAID-Controllers wahrscheinlich veraltet war und deshalb falsche Dinge anzeigte. Nachdem ich den maxView-Storage-Manager installiert hatte und darüber die Systemsoftware des RAID-Controllers aktualisiert hatte, war das Problem behoben und die Anzeige sah so aus, wie oben auf dem Bild.
Eine zweite Falle ist die Anleitung zur Aktualisierung der Systemsoftware in der Bedienungsanleitung und auf der Homepage von Adaptec bzw. Microsemi. Angeblich muss man sich bei Microsemi einen Support-Account anlegen, dann dort im Support die neue Software herunterladen und installieren. Nach mehreren Stunden hatte ich dort aber trotz Anmeldung immer noch keine Seite mit einem Download gefunden.
Der Support hat mir dann den Link zum Firmware-Update des RAID-Controllers geschickt, aber mit dem maxView-Storage-Manager geht es noch einfacher und zwar auf Knopfdruck. Weiter unten mehr zu dieser Verwaltungssoftware für das RAID.
Achtung:
Die „CNX-Bezeichnungen“ beziehen sich immer auf eine Buchse (mini SAS HD connector x 4) auf dem RAID-Controller, in die ein Vierfach-Kabel kommt, das sich zu den Festplatten hin in vier einzelne Kabeln aufspaltet. Die Lage auf der Zeichnung in der Bedienungsanleitung, wie oben schon erwähnt, ist falsch. Im maxView-Storage-Manager werden aber auch die Festplattenseriennummern angezeigt und man kann ziemlich einfach herausfinden wo z. B. Buchse CN0 oder CN4 ist. Danach sollte man die Kabel mit einem Schild ebenfalls beschriften, damit man später noch weiß, was wohin gehört.

mini SAS x 4 HD Connector-Kabel
Hier kommt noch eine sehr nützliche Seite im Raid-Controller-BIOS, nämlich die Temperaturkontrolle des Flash-Backup-Moduls und dessen Stromversorgung. Das Backup-Module ist bei mir unterhalb des Netzteils verschraubt, also außerhalb jeglicher Hitzeansammlungen.
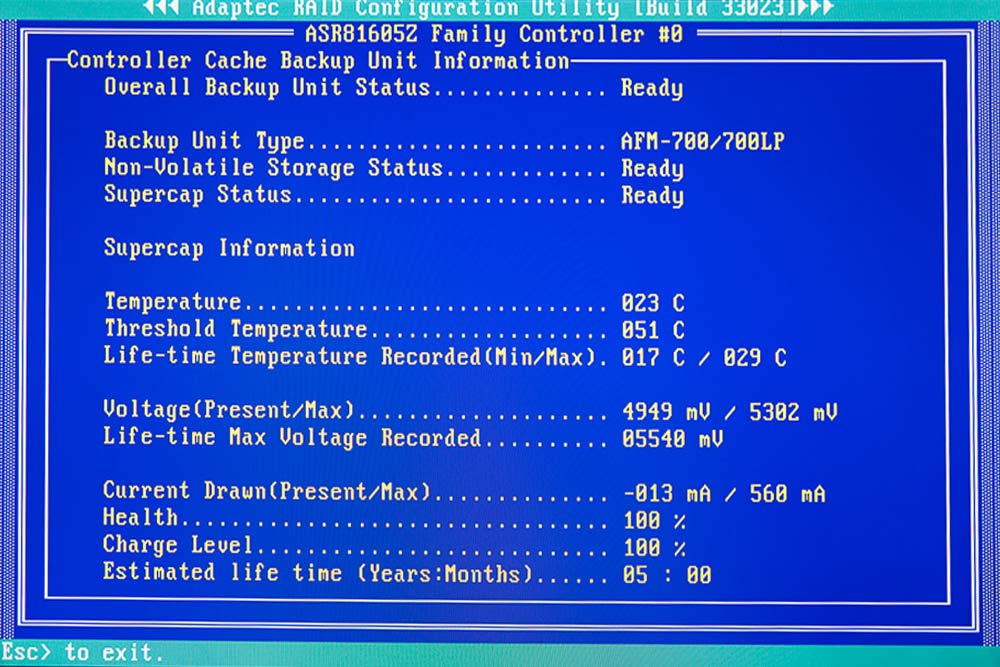
Temperatur Flash-Backup-Modul
BIOS-RAID-Controller, falls man Änderungen vorgenommen hat, speichern nicht vergessen!
IV. Ubuntu-Server installieren
Vorarbeiten
Folgende Vorarbeiten sind erledigt:
- SSD Platte angemeldet
- IPMI funktioniert und wir können von der Ferne schon die Kerndaten des Mainboards sehen
- BIOS ist auf UEFI umgestellt
- Secure Boot ist aus
Was liegt zu diesem Zeitpunkt noch im Argen?
- die Lüfter pumpen, da sie ständig unter die Mindestdrehzahl des Mainboards gehen
Lösung: ipmitool, ein Linux-Programm - die Systemsoftware des RAID-Controllers ist veraltet, das BIOS zeigt falsche Werte an
Lösung: maxView-Storage-Manager
Ubuntu-Server installieren Vorgehen
Auf der Seite von Ubuntu kann man die aktuelle Server-Long-Term-Version herunterladen. Achten Sie darauf, dass Sie die LTS-Version aussuchen. Es gibt auch spezielle Versionen z. B. für ARM-Chips. Bei mir war es die „Ubuntu Server 16.04.1 LTS“.
Man bekommt eine iso-Datei, die nun auf einen USB-Stick, in einer ganz bestimmte Formatierung (startfähig), kopiert werden muss. Unter Linux ist dies einfach, aber wir gehen hier davon aus, dass Sie vielleicht noch keinen Linux-Desktop-Rechner eingerichtet haben. Die Vorgehensweise beim Mac ist etwas komplizierter, klappt aber dank „Terminal“ auch. Später habe ich festgestellt, dass es am Mac jedoch Probleme mit der Verifizierung geben kann.
Linux startfähiges USB-Stick-ISO-Image am Mac erstellen
- Teminal am Mac öffnen
- folgendes eingeben:
hdiutil convert -format UDRW -o linuxServer.img /PFAD/Ubuntu.iso
- und dann nach einem Leerzeichen, die ISO-Datei von Ubuntu mit der Maus dahinter ziehen, damit schreibt das Terminal automatisch den Pfad der Datei ins Terminal – „linuxServer.img“ ist die Zieldatei, sie landet automatisch in Ihrem Heimatverzeichnis auf dem Mac, also das Verzeichnis das so heißt wie der User (macht man ein Finder-Fenster auf, dann ist es links in der Liste unter dem Benutzernamen zu finden)
- Nach erfolgter Kovertierung manuell das „.dmg“ am Dateinamen entfernen, so dass sie wirklich „linuxServer.img“ heißt und auf den Schreibtisch ziehen
- dem USB-Stick geben wir einen eindeutigen Namen z. B. „LINUX-SERV“
- im Terminal finden wir heraus, wie der Mac den USB-Stick intern bezeichnet, bzw. seinen Einhängepunkt
- im Terminal geben wir ein:
diskutil list - anhand der Größe, der Angabe „DOS_FAT_32“ und anhand des Namens finden wir den Einhängepunkt des USB-Sticks – bei mir „/dev/disk3/“
- nun geben Sie im Terminal den folgenden Befehl ein mit Ihrer Nummer ACHTUNG alle Daten auf dem USB-Stick werden gelöscht und sind Sie wirklich sicher, dass es die Nummer des USB-Sticks ist? Lieber zweimal prüfen! Fragezeichen in folgendem Befehl mit Nummer ersetzen:
diskutil unmountDisk /dev/disk? - nun kommt das Überspielen des linuxServer-Images auf den Stick:
sudo dd if=/Users/thomas/Desktop/linuxServer.img of=/dev/rdisk3 bs=1m
nach „if=“ einfach wieder die linuxServer.img-Datei mit der Maus hinziehen – rdisk? muss Ihre Nummer erhalten, die Sie weiter oben ermittelt haben - man muss das Admin-User-Passwort eingeben, dann dauert es eine ganze Weile bis im Terminal die Übertragung bestätigt wird und ein Popup-Fenster erscheint mit dem man den USB-Stick auswirft – „Auswerfen“ klicken!
- USB-Stick abziehen
Wem das alles zu kompliziert ist, der kann es auch einfacher haben mit dem Mac-Programm Unetbootin oder unter Windows oder am einfachsten am Linux-Desktop mit dem startup-disk-creator.
Eine Suche im Netz ergibt etliche Anleitungen z. B. die für den Mac von timSchropp, auf die ich mich beziehe.
Linux startfähiges USB-Stick-ISO-Image am Ubuntu-Desktop erstellen
Als erstes kann man beim Installieren des Ubuntu-Servers den USB-Stick auf Konsistenz mit einer Prüfziffer analysieren. Leider schlug dies bei mir nach der Mac-Prozedur fehl. Es gab eine Inkonsistenz bei einer Datei. Der Stick hatte trotzdem soweit funktioniert, dennoch habe ich mit dem Ubuntu-Desktop-Rechner einen neuen Stick erstellt. Eine Anleitung findet man auf der Ubuntu-Internetseite unter create-a-usb-stick-on-ubuntu.
Ubuntu-Server auf dem neuen Server installieren
USB-Stick in die Buchse und den Server neu starten.
Es kommen diverse Abfragen, nach Land, Uhrzeit, Tastatur etc.
Netzwerk einrichten
Dann eine Abfrage nach der Netzwerkverbindung. Ich habe erst mal alles mit DHCP automatisch einrichten lassen und den 10GBASE-T-Netzwerkadapter gewählt. Um Duplex und dergleichen kümmere ich mich später. Wenn der Switch nur Gigabit hat, macht es unter Umständen auch Sinn 10GBASE-T ganz zu deaktivieren, da dessen Prozessor ganz schön warm wird (momentan das heißeste Bauteil auf dem Mainboard), also Strom in sinnlose Hitze verwandelt. Auf der anderen Seite kann man beim 10 GB Anschluss sicher sein, dass er bei 1 GB auch das Maximum was möglich ist liefert.
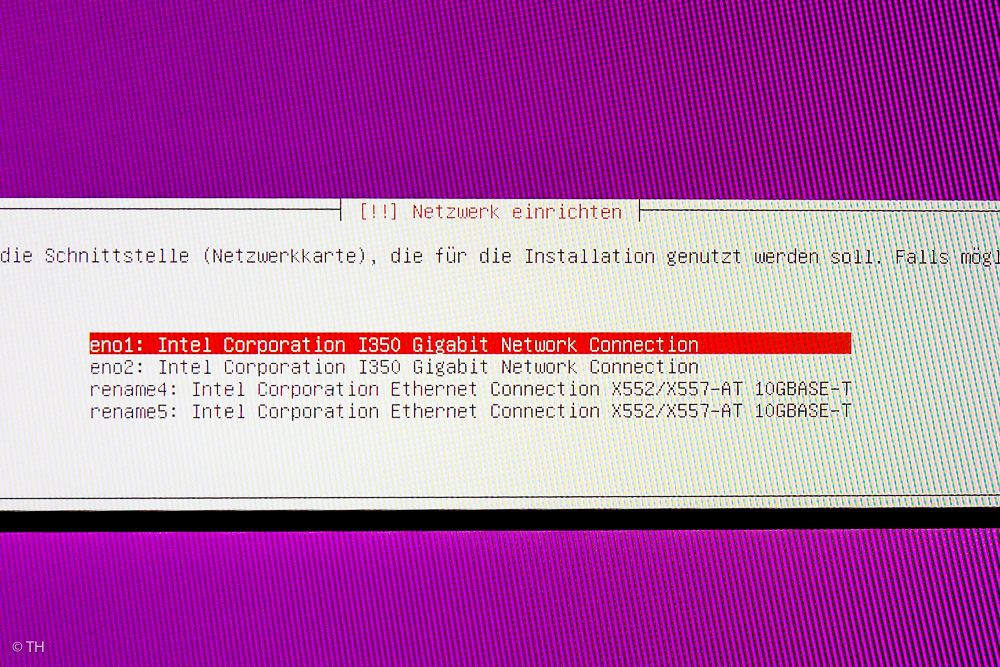
Netzwerk einrichten
Festplatte partitionieren
Hier gab es einen ordentlichen Knoten, der sich lange einer Lösung verweigert hat:
Man sucht sich zuerst die komplette SSD aus und wählt „Manuell„. Alles was „Geführt“ heißt, bedeutet nicht „geführt“, sondern automatisch ohne Einflussnahme!
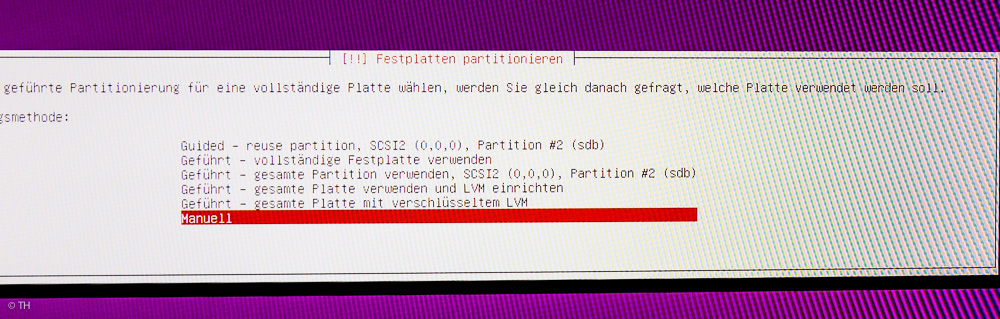
Partionierung der Festplatte Linux-Ubuntu-Server
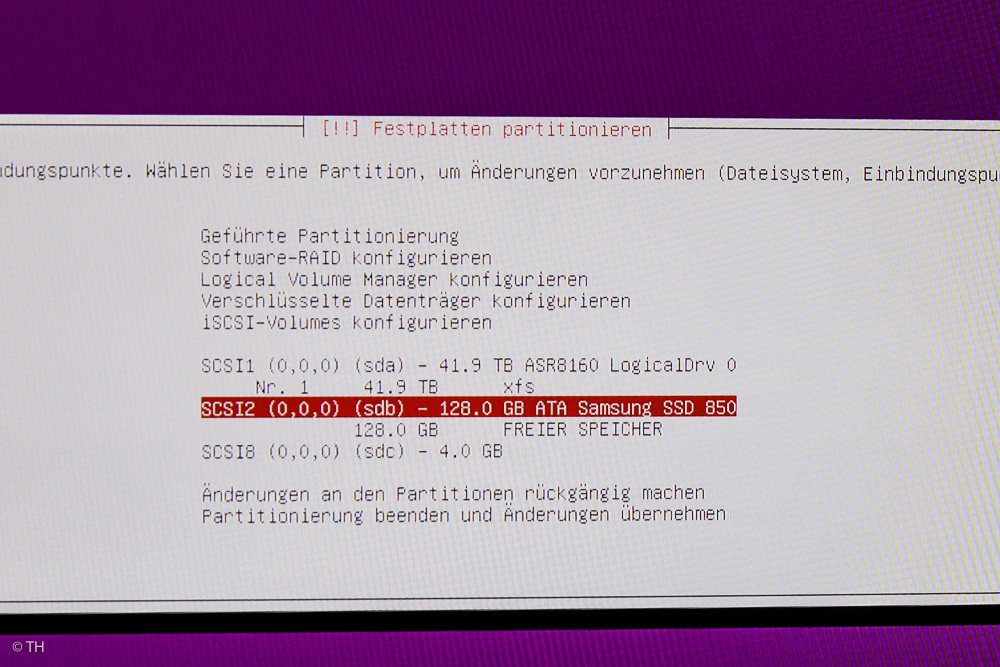
ganze SSD verwenden
Das Mainboard haben wir auf UEFI gestellt. Die SSD-ist bereit komplett überschrieben zu werden, da sie nur das Linux-System aufnehmen soll und sonst weiter nichts. Das Home-Verzeichnis wird im Großen und Ganzen wahrscheinlich nicht benutzt werden, da alle Daten auf das RAID gehen. Man kann die SSD, wenn man sie vorher benutzt hat, mit dem Terminal am Mac komplett von allen Partionen befreien, um sicher zu gehen, dass nicht mehrere EFIs angelegt werden, aber es geht auch ohne.
Dennoch kommt am Anfang eine Meldung, ob man wirklich mit EFI fortfahren will, da es anscheinend noch andere Betriebssysteme auf der SSD gibt. Diese gibt es nicht, also ruhig mit „Ja“ beantworten und mit EFI fortfahren und der Erstellung einer leeren Partionstabelle für die ganze SSD fortfahren.

UEFI und angeblich schon vorhandene Betriebssysteme, die es gar nicht gibt.
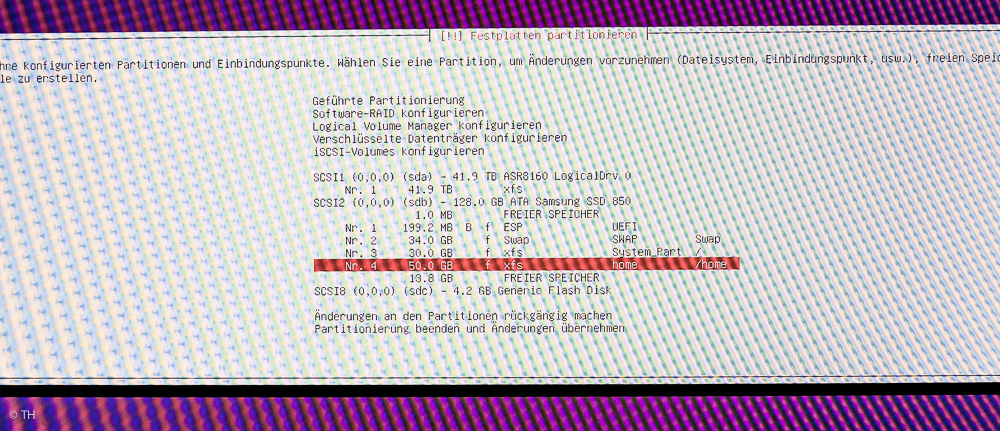
UEFI Ubuntu und xfs
Partionen für den Ubuntu-Server
- EFI-Partion mit 200 MB
- Swap-Partion mit 34 GB (2 GB mehr als der Arbeitsspeicher, Swap ist die Auslagerungspartion für den Arbeitsspeicher, falls er zu voll wird)
- System-Partion gemountet an ROOT: / – Größe 30 GB mit dem Dateisystem xfs ??? (es würden auch 20 GB reichen)
- Home-Partion gemountet an /home – Größe 50 GB mit dem Dateisystem xfs
- Rest als FREIER SPEICHER, falls man später irgendwo noch etwas braucht
Erst mal ist mir aufgefallen, dass automatisch immer vor der ersten Partion ein freier Speicherblock von 1 MB automatisch eingebaut wird. Das muss so sein, eine Erklärung gibt es unter: Ubuntu-Partionierung leerer Block mit 1 MB
Das ging soweit alles ganz gut, doch als ich den Server starten wollte landete ich immer bei der „grub-Bash“ mit dem Eingabe-Prompt: „grub>“.
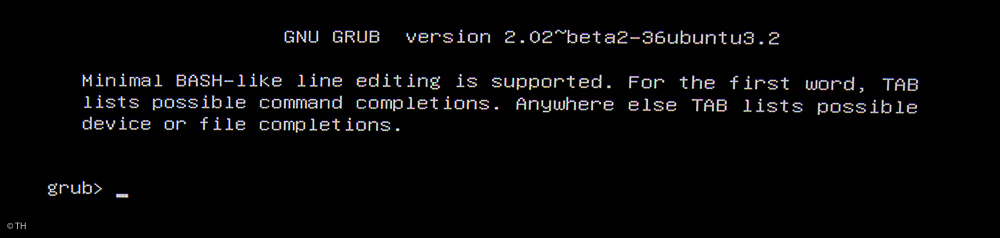
grub-bash
Nach zweimaliger Eingabe von „exit“ landet man bei der „EFI-Bash“. Der Grub-Loader hatte also irgend ein Problem mit dem Laden des Kernel.
Beim Ubuntu-Desktop hatte ich ähnliche Angaben gemacht und da ging es, als ich ihn zum Testen auf dem Server installiert hatte. Mein erster Versuch war eine automatische Partionierung mit „Geführt – ganze Festplatte verwenden“ und siehe da es ging. Gab man in der Grub-Bash „ls“ ein und versuchte mit „ls“ wiederum den Inhalt der gelisteten Partionen anzuzeigen kam: „Dateisystem kann nicht gelesen werden“. Also habe ich meine manuelle Partionierung nochmals durchgeführt, aber dem System das Dateisystem „ext4“ mitgegeben und siehe da es ging plötzlich. Home habe ich auf „xfs“ gelassen.
Achtung:
Das Dateisystem „xfs“ geht nicht für die Systemdateien und GRUB bei Ubuntu-Server 10.16, es muss für das System z. B. „ext4″ gewählt werden!
Das hängt vielleicht damit zusammen, dass „xfs“ keinen Platz für einen Boot-Sektor lässt, den es bei EFI aber eigentlich gar nicht braucht? Hat jemand eine schlaue Erklärung?
(Stand Oktober 2016)
Sicherheitsupdates

Sicherheitsupdates Ubuntu
Sicherheitsupdates sollen automatisch installiert werden, andere Aktualisierungen macht man lieber manuell, damit sie nicht das System lahmlegen.
Software Pakete jetzt zusammen mit dem Ubuntu-System installieren
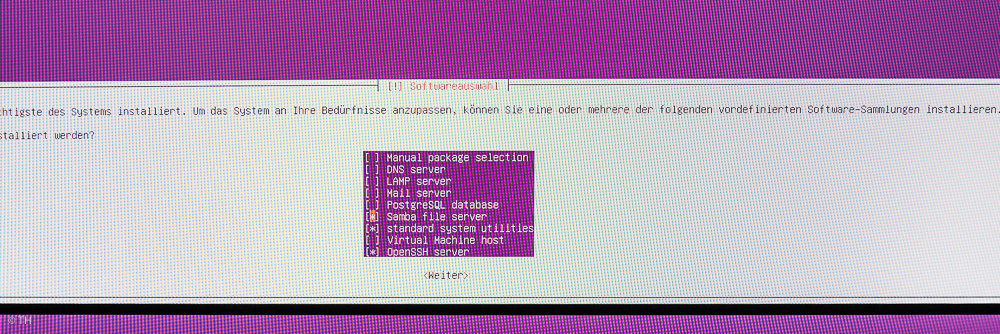
Ubuntu-Server Software-Sammlungen installieren
Man braucht die „standard system utilities“, „OpenSSH server“ und „Samba File server“. Alles andere kann man später installieren, da man z. B. nicht einen vollen Mail-Server braucht um Mails bei Systemproblemen zu verschicken etc.
OpenSSH braucht man für die Fernwartung und der Samba-File-Server bildet den Kern unseres Fileservers.
Ubuntu stellt die Pakete zusammen und löst auch Abhängigkeiten auf, die zwischen Paketen bestehen, so dass immer alles gut zusammenpasst.
Ubuntu-Installation fertig

Ubuntu fertig installiert
Nach einigen Minuten ist Ubuntu-Server fertig installiert. Wer die Abläufe nochmals im Detail nachlesen will findet Hilfe und Anleitungen auf der Ubuntu-Internetseite. Leider gab es keine Hinweise zum meinen Problemen mit dem Dateisystem „xfs“, das sich hauptsächlich für große Datenmengen eignet, aber von einigen Distributionen, auch so wie ich es vorhatte, generell eingesetzt wird.
Der kleine Hinweis am Bildschirm erinnert daran, dass man beim Neustart noch den USB-Stick abziehen sollte, da man sonst zwangsläufig wieder im Installationsmodus landet. Der Server startet neu und wenn man Glück hat bleibt der Startvorgang nicht an der Grub-Bash hängen, sondern fängt an etliche Dateien zu laden, bis er schließlich bei einem charmanten Eingabepromt in der Bash endet.
Ende gut alles gut!
Nicht ganz das Ende, aber jetzt geht es weiter in der Welt von LINUX.
Von nun an kann man alles über SSH, bequem vom Schreibtisch aus weiter installieren und einstellen. Ich benutze dazu das Terminal am Mac.
Einloggen mit SSH am Server
Am Mac öffnet man das Terminal und gibt folgendes ein, falls man am gleichen Router wie der Server hängt:
SSH username@servername
oder
SSH username@IP-address
Danach wird man noch aufgefordert sein Passwort anzugeben, jetzt wird man verbunden. Beim ersten Mal wird der Fingerprint noch angegeben, d. h. der Sicherheitsschlüssel und man muss bestätigen, dass man dem Schlüssel vertraut und sich mit dem Server verbinden will.
Nachdem ich den Ubuntu-Server nochmals ganz neu eingerichtet habe (Versuch die RAID-Controller-Treiber einzurichten) musste ich am Mac erst den alten Sicherheitsschlüssel löschen, da der Mac bei zwei unterschiedlichen Schlüsseln vom Server mit dem selben Namen, eine „Man-in-the-middle-Attack“ vermutete.
Die ganze Software auf den neuesten Stand
Bevor man weitere Einstellungen vornimmt kann man die ganze Software einmal abgleichen und dann auf den neuesten Stand bringen. Das „-y“ sorgt dafür, dass Rückfragen (z. B. ob Abhängigkeiten mit aktualisiert werden sollen) automatisch mit „Ja“ beantwortet werden:
sudo apt-get update && sudo apt-get upgrade -y
Manchmal müssen bei einem Upgrade auch zusätzliche Pakete installiert werden, dies macht die obige Zeile nicht. Es kommt die Meldung: „Die folgenden Pakete sind zurückgehalten worden“. Will man beim Upgrade auch neue zusätzliche Pakete landen, dann braucht es diesen Befehl:
sudo apt update && sudo apt full-upgrade
Ein aufgeschobenes Problem behandeln: Die pumpenden Lüfter
 Die rote Warnlampe Item 51/LED 8 : Dauerleuchten = Überhitzung, Blinken = PWR/PWM-Fehler oder Lüfterausfall. Bei mir hat sie geblinkt.
Die rote Warnlampe Item 51/LED 8 : Dauerleuchten = Überhitzung, Blinken = PWR/PWM-Fehler oder Lüfterausfall. Bei mir hat sie geblinkt.
PWM Lüfter und PWR
PWM ist die Pulsweitenmodulation des Lüfters, ein Steuersignal des Mainboards gibt ein 25 kHz Signal an die Lüfterelektronik um den Lauf zu steuern. PWR steht denke ich für engl. „Pulse Width Regulation“ des Mainboards.
Wie wir im „Teil 1 – Hardware“ festgestellt haben, pumpen die zwei noctua-Lüfter. Sie fallen langsam auf eine niedrige Geschwindigkeit ab und das Mainboard steuert sofort dagegen, indem es die beiden 15 cm-Lüfter wieder auf ihre Maximalumdrehungszahl hochfährt. Dies liegt daran, dass das Mainboard von kleinen Lärmlüftern ausgeht, die direkt auf die Kühlkörper geschraubt sind und mindestens mit 700 U/Min. drehen sollen. Stellt das System fest, dass die Lüfter unter diesen Wert (Threshold) abfallen, werden sie künstlich wieder hochgefahren. Der Lösungsversuch des Problems besteht darin im System den „Threshold“ für die Lüfter zu ändern:
ipmitool installieren und gegebenenfalls die Kernelmodule laden
sudo apt install ipmitool
versucht man nun ipmitool zu starten mit
ipmitool sensorkommt
Could not open device at /dev/ipmi0 or /dev/ipmi/0 or /dev/ipmidev/0: No such file or directory
Manchmal müssen erst noch entsprechende Kernelmodule dauerhaft eingeschaltet werden:
sudo modprobe ipmi_devintf
sudo modprobe ipmi_msghandler
sudo modprobe ipmi_poweroff
sudo modprobe ipmi_si
sudo modprobe ipmi_watchdog
(Details zu den IPMI-Modulen gibt es hier.)
Sollen diese immer beim Start geladen werden, dann muss man sie in /etc/modules Zeile für Zeile eintragen. Habe ich aber nicht gemacht, da sie trotzdem geladen wurden. Geladene Kernelmodule kann man anzeigen lassen mit:
sudo lsmod
Weiter mit dem ipmitool-Programm:
sudo ipmitool sensor
Das Ziel sind die folgenden Einstellungen für die großen noctua-Lüfter. Zu finden sind die Drehzahlen auf der noctua Homepage beim jeweiligen Lüftermodell.
sens|aktuell |Maß| Status| LNR | LCR | LNC | UNC | UC | UNR |
FAN1|400.000 |RPM| ok |100.000|200.000|300.000|1300.000|1400.000|1500.000
FAN2|300.000 |RPM| nc |100.000|200.000|300.000|1300.000|1400.000|1500.000
Die Abkürzungen bedeuten:
Lower Non-Recoverable = LNR
Lower Critical = LC
Lower Non-Critical = LNC
Upper Non-Crititical = UNC
Upper Critical = UC
Upper Non-Recoverable = UNR
Die weiteren Abkürzungen sind:
cr = critical
nc = non-critical
nr = non-recoverable
ok = ok
ns = not specified
Zum Ändern der Werte gibt man folgendes einmal für „lower“ und einmal für „upper“ ein:
ipmitool sensor thresh "*sensor name*" lower *lnr* *lcr* *lnc*
sudo ipmitool sensor thresh "FAN2" lower "100" "200" "300"
ipmitool sensor thresh "*sensor name*" upper *unc* *ucr* *unr*
Die Sternchen UND die Abkürzungen müssen natürlich ersetzt werden.
Eine sehr gute ipmitool-Anleitung gibt es im freenas-Forum.
Oder hier bei Thomas Krenn für die Thresholds und generell zum ipmitool.
Achtung:
Innerhalb des IPMI-Zugangs auf das Board muss im dortigen Menü unter: „Configuration – Fan Mode“, folgende Auswahl getroffen werden: „Set Fan to Optimal Speed„.
Problem:
Bei meinem Board ist es so, dass die neuen Thresholds zwar gespeichert werden (im SDR-sensor-data-record -> siehe Link Thomas Krenn/Thresholds) und auch beim Neutstart wieder da sind, dass aber die Lüfter manchmal sehr lange brauchen (ein paar Stunden) bis sie sich einpendeln oder ich muss den Server neu starten (Strom weg und 30 Sekunden warten, setzt IPMI zurück) und hoffen, dass sie danach tatsächlich nicht mehr pumpen. Dafür habe ich noch keine Lösung und auch keine Hilfe/Idee von Supermicro bekommen.
Eine interessante Anmerkung von Thomas Krenn ist, dass manche Supermicro-Boards nur Lüfterwerte im Abstand von 135 U/Min erlauben. Das wäre dann:
sudo ipmitool sensor thresh "FAN1" lower "135" "270" "405"
sudo ipmitool sensor thresh "FAN2" lower "135" "270" "405"
Aber auch das hat bei mir keine Lösung gebracht.
Was momentan hilft, ist einfach den Server so oft neu zu starten (wirklich Strom weg und 30 Sekunden warten), bis es dann funktioniert und die Lüfter stabil mit 300-400 U/Min. laufen.
Die Spezifikation zu IPMI gibt es bei Intel als PDF und sie sagt, dass natürlich nur vom Hersteller vorgesehene Werte eingestellt werden können.
Eine momentane Lösung für die Lüfter, die funktioniert
Da die Lüfter nicht dauerhaft unter Kontrolle gebracht werden können, gibt es noch eine „Hardware-Teillösung“:
noctua-Lüfter werden mit einem kleinen Zwischenkabel (low noise adapter / L.N.A) ausgeliefert, das die maximale Drehzahl des Lüfters insgesamt begrenzt. Damit geht der Lüfter, falls er in den Pumpmodus verfällt nicht mehr über 900 U/min.
noctua: „Der NF-A15 PWM wird mit einem (L.N.A.) ausgeliefert, der die Maximalgeschwindigkeit von 1200 auf 900 rpm reduziert. Damit können Sie den Lüfter entweder mit konstanten 900 rpm betreiben oder die maximale Geschwindigkeit im PWM Betrieb begrenzen.“
Zusätzlich habe ich den oberen Lüfter im „Winterbetrieb“ abgeklemmt, so dass nur noch ein Lüfter betroffen ist, der dann auch im Zweifelsfalle höher drehen wird und somit nicht meh unter den Schwellwert von 300 U/min fällt.
SuperDoctor5 von Supermicro
SuperDoctor5 ist ein Programm des Mainboardherstellers Supermicro, das ebenfalls die ganzen Sensoren überwacht und graphisch darstellt. Man kann es auch remote über das Netz aufrufen und es gibt die Möglichkeit Emails zu verschicken, falls Fehler auftreten.
http://www.supermicro.com/products/nfo/sms_sd5.cfmsudo
Ich habe es nicht installiert, da es sich mit IPMI doppelt und bei meinem Testlauf keinen Zusatznutzen brachte.
Linuxprogramm lm-sensors
Ein Linuxprogramm, das ebenfalls diverse Sensoren anzeigt:
sudo apt-get install lm-sensors
sudo sensors-detect
V. Den RAID-Controller und das RAID einrichten
Erst mal schauen, was am Server so alles vorhanden ist an Festplatten und siehe da, das RAID funktioniert von Anfang an:
blkid -o list
Man bekommt eine ausführliche Liste aller „gemounteten“ und auch der „nicht-gemounteten“ Festplatten und Partionen. Auch das RAID wird angezeigt und kann auch gemountet werden. Inhalte können geschrieben werden etc.
Auf meinem Mainboard sind damit anscheinend Treiber vorhanden, die den RAID-Controller steuern können. Adaptec gibt zwar an, dass es besser wäre, die Adaptec-Treiber zu verwenden, aber momentan liegen noch keine Treiber für die erste Update-Version von Ubuntu 16.04 LTS also Ubuntu 16.04.1 vor. Will man originale adaptec-Treiber installieren, begibt man sich auf eine große, steinige Reise mit tiefen Gräben und schwarzen Löchern:
Es gibt zwei Möglichkeiten, einmal direkt mit dem Ubuntu-Betriebssystem installieren und einmal danach am schon bestehenden Ubuntu-System.
Adaptec-RAID-Controller-Treiber für Linux 16.04 installieren
Auf der Seite start.adaptec.com gibt man die Bezeichnung des RAID-Controllers ein, bei mir ist dies: Adaptec RAID 81605ZQ.
Manchmal gerät man dann in die Produktregistrierung und manchmal wird man weitergeleitet zur Betriebssystemauswahl. Das neueste was momentan (Okt. 2016) geboten wird ist Ubuntu 14. Wenn man dort klickt kommt man zu „Ubuntu 14.04 LTS Downloads“ und findet dort den Treiber: AACRAID Drivers v1.2.1-52011 for Linux.
Klickt man wiederum auf den Treiberlink sieht man Details und siehe da unter Beschreibung steht: Ubuntu 14.04.4 and 16.04. Der Treiber passt also zu Ubuntu 14.04.04 und zum ersten Release von Ubuntu 16.04 aber nicht zu Ubuntu 16.04.1.
TIPP:
Immer über www.adaptec.com gehen, nach der Weiterleitung unten rechts in der Textspalte auf „Microsemi Adaptec Support“ klicken, dann über die Produktauswahl weiter. Alles andere führt in die Untiefen einer recht konfusen Internetseite von Microsemi.
Wenn es den neuen Treiber gibt, geht das Vorgehen am schon bestehenden Ubuntu-System so:
Das Treiberarchiv (tgz mit 150 MB) lädt man herunter und entpackt den passenden Ordner für ubuntu_16.04.1. Darin befinden sich nun Ordner für PowerPCs (Apple) „ppc64le“ und normale „x64“, als „tgz“ und als „deb“. Wir brauchen nur die „deb-Datei„, die man auf einen USB-Stick kopiert.
(Im tgz-Archiv verbergen sich die Dateien für einen Installation während man Ubuntu-Server installiert, zusammen mit einer README.txt-Anleitung. Dieses brauchen wir aber jetzt nicht.)
Das Shell-Kommando, das wir anwenden ist „dpkg“.
Debian Package „dpkg“ installiert einzelne „.deb-Packete“ / -i = install
Eigentliche Installation des Treibers für den RAID-Controller auf ein bestehendes System
Den Ubuntu Packet-Index aktuallisieren:
sudo apt-get update
Falls sie noch fehlen, entsprechende Entpackungstools laden:
sudo apt-get install build-essential
Den USB-Stick einstecken und dann schauen wo er ist, das geht wieder mit „blkid“:
blkid -o list
Den USB-Stick mit dem Treiber darauf mounten (bei mir /dev/sdc1):
sudo mount /dev/sdc1/ /media
Treiber installieren:
sudo dpkg -i /media/aacraid-1.2.1-52011-Ubuntu16.04-x86_64.deb
Bei mir schlägt es fehl, da das Installationsprogramm versucht in „4.4.0-21-generic“ zu installieren, aber der neue Kernel bei der Ubuntu-Version 16.04.1 heißt schon „4.4.0.31“!
Es gibt damit schlichtweg keinen Ordner mit der Bezeichnung „4.4.0-21-generic“.
Es soll in ein paar Monaten den aktuellen Treiber geben (Stand Oktober 2016).
Installation des Treibers für den RAID-Controller zeitgleich mit dem Ubuntu-System
Man kann den Treiber auch schon zusammen mit dem Ubuntu-OS-System installieren (beide zur selben Zeit), aber hier ist ein ähnliches Problem, folgt man der Anleitung, die im Archiv
„aacraid-1.2.1-52011-Ubuntu_16.04-Boot-x86_64.tgz“ mitgeliefert wird, dann kann man zwar den richtigen Kernel-Ordner-Namen angeben, bekommt am Ende aber ein „invalid module format aacraid.ko“.
Achtung:
Es kommt wirklich darauf an, dass man genau die richtige Version verwendet! Laut Hotline von adaptec in ein paar Monaten erhältlich.
maxView Storage Manager zur RAID-Verwaltung installieren
Der maxView Storage Manager ist ein schönes graphisches Programm, das bei Desktops direkt auf dem System perfekt funktioniert. Man kann RAIDs einrichten, Sensoren überwachen und sich eine Email schicken lassen, falls eine Störung auftritt.
Bei einem Server wird die Sache schwieriger. Es gibt verschiedene Möglichkeiten:
- BIOS des RAID-Controllers zur Verwaltung nutzen
- Mit einem bootfähigen USB-Stick, auf dem ein System plus maxView Storage Manager und das Kommandozeilenprogramm ARCCONF drauf ist, kurzfristig arbeiten.
- Command-Line-Utility ARCCONF und adaptec Event Monitor im Hintergrund, der Meldungen absetzt.
- Auf dem Ubuntu-Server maxView Storage Manager installieren (mit einem Apache Tomcat – CIM Server) und dann aus der Ferne über das Netzwerk mit einem Browser zugreifen.
zu:
- Das BIOS ist nicht schlecht und für fast alle Aufgaben geeignet, Email-Benachrichtigung geht nicht, Systemupdate ist auch nicht möglich.
- Da man nur vom USB-Stick bootet und ein Minisystem hat, hat man keinen Internetzugang und kann z. B. keine Systemaktualisierungsdatei herunterladen. Die Menüs scheinen gekürzt im Gegensatz zur Vollversion. Email-Benachrichtigung geht nicht, da der USB-Stick ja wieder weg kommt.
- Die Command-Line-Utility ARCCONF ist, soweit ich das sehen konnte, nicht gerade übersichtlich, hat aber alle nötigen Befehle.
- Fernwartung mit maxView und CIM-Server-Installation auf dem Server, der die Überwachung weiterleitet. Aufwendig und noch ein Serverprozess der läuft (Ist der sicher? – Wie ist der CIM-Server eingerichtet?), aber das Übersichtlichste, wenn mal eine Platte ausfällt und man einen Überblick braucht, was wo zu tun ist. In der Angst bei einem Festplattenausfall seine Daten zu verlieren macht man schnell mal einen Fehler, deshalb ist es wichtig ein einfaches und übersichtliches Programm zu haben.
1. Einstellungen und RAID anlegen im BIOS
Während des Startvorgangs „CTRL+a“ drücken, dann kommt man ins RAID-Controller BIOS. Das geht komfortabler als man denkt.
2. Einstellungen und RAID anlegen vom bootfähigen USB-Stick mit maxView
Unter www.adaptec.com wählt man in der rechten Spalte, rechts unten „Microsemi Adaptec Support“, dann klickt man sich über sein Produkt durch, bis man bei den Downloads ist, dort auf „Storage Manager Downloads“ dann kommt man auf bootable USB-Image.
Dieses Image herunterladen und als bootfähigen USB-Stick brennen. Hier versagt leider der oben erwähnte „Linux-create-boot-image-Agent“ des Ubuntu-Desktop-Systems, da er sich nur um Ubuntu-iso-Dateien bemüht und diese hier schnöde ignoriert. Es kommt also der nächste Agent zum Einsatz (die Mac-Terminal-Nummer – siehe weiter oben – hat wieder nicht funktioniert):
Diesmal ein Fedora-Programm für Windows. Man lädt den Fedore-USB-Creator herunter und installiert ihn auf einem Windows-Rechner (Fedora würde natürlich auch gehen.) Man muss das Programm mit einem „Rechtsklick“ starten, damit es mit Administratorrechen läuft! Dann brennt man damit das iso-Image auf den Stick.
Will man die Boot-Sequenz im BIOS des Ubuntu-Servers umstellen, muss man darauf achten, dass man von „EFI“ auf „DUAL“ umschaltet und dort den USB-Stick nach vorne holt, denn auf „EFI“ lädt der bootfähige USB-Stick natürlich nicht. Einmal neu starten und schon ist man in einem schönen Live-System und kann mit Firefox, nachdem man ihn als „Standard-Browser“ (wichtig!) ausgewählt hat, mit dem Benutzer „root“ und dem Passwort „root“ alle Einstellungen am RAID vornehmen.
Wie man von da aus eine Datei zum RAID-Controller-Systemupdate lädt, habe ich aber nicht herausgefunden, ich denke mal, dass es schlicht weg nicht geht, da dieses System weder über Internet verfügt noch andere USB-Sticks einbinden kann.
Da der Stick nach getaner Tat wieder weg kommt, kann man ihn natürlich auch nicht das System überwachen lassen, der Email-Versand bei Fehlern fällt also auch weg.
3. Commandline-Tool auch mit CIM-Server
Das Paket „Adaptec Event Monitor“ kommt zusammen mit dem Command-Line-Tool ARCCONF. Da das Commanline-Tool ebenfalls einen CIM-Server einrichtet, kann man sich die Mühe sparen und gleich zum graphischen maxView-Storage-Manager wechseln.
4. maxView Storage Manager mit CIM-Server und Fernwartung
Den Storage-Manager gibt es wieder auf der Adaptec Internetseite unter maxView Storage Manager. Man bekommt ein Archiv mit dem Manager und dem Commandline-Tool. Im Ordner des Managers gibt es verschiedene Dateien für Linux 64 bit und meinem Prozessor gilt die „xxx.deb-Datei“.
Die Datei auf den Server laden und dann installieren (die „X“ stehen für verschiedene Versionen, je nachdem wie die Datei zum aktuellen Zeitpunkt heißt):
dpkg-i StorMan-X.XX-XXXX_amd64.deb
Entgegen den Behauptungen der Bedienungsanleitung kann man nicht „nur den Dämon ohne die graphische Oberfläche“ anwählen. Stattdessen kommt am Schluss eine Fehlermeldung, dass das Desktop-Symbol nicht platziert werden konnte, da es keinen Desktop gibt.
Folge Angaben kann man während der Installation machen:
CIM Server HTTP Port: [default: 5988] – ich habe 5988 angegeben am Ende ist es aber doch 8443 geworden, warum auch immer. Dies kann man aber später bei Bedarf anpassen. (Beim CIM-Server handelt es sich um ein Apache-Tomcat -Modul).
TIPP:
Am Router sollte man dafür sorgen, dass die ganzen Ports, die intern genutzt werden, vom Internet aus geschlossen sind, höchstens man möchte von unterwegs das RAID steuern (Z. B. den Alarm ausschalten, damit die Nachbarn wieder schlafen können nach einem Festplattenausfall, denn der RAID-Controller produziert bei Problemen eine lautes Pfeifen.).
LocalHost Mode: [default: No] – hier muss auf alle Fälle „No“ stehen, sonst geht die Fernwartung nicht und der Storage Manager erwartet das RAID auf dem eigenen Rechner (localhost).
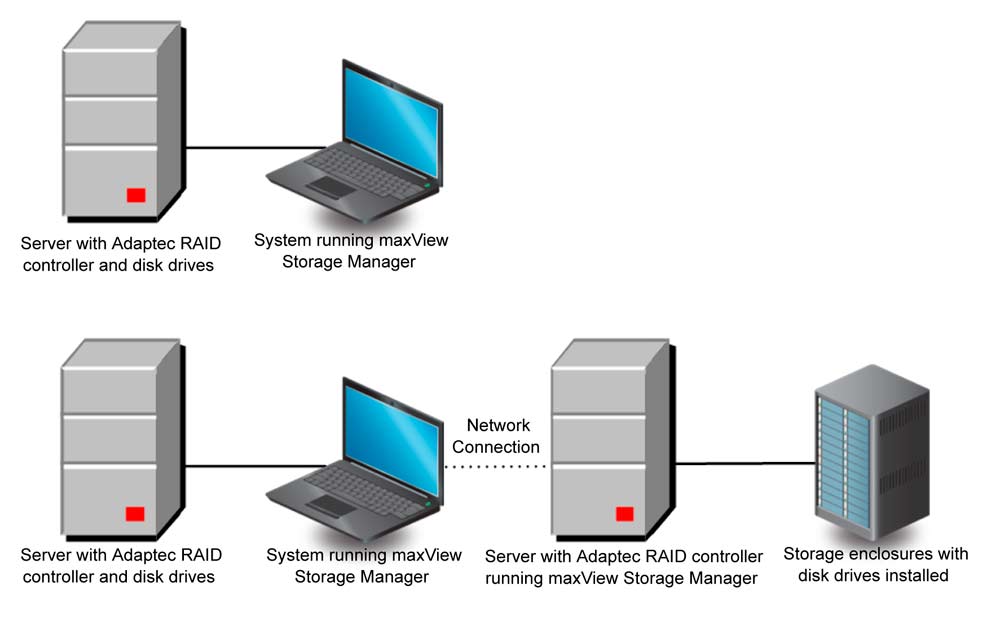
maxView Storage Manager – bei mir ist es die „Network Connection“
Fernzugriff auf den Server mit dem maxView Storage Manager
Entgegen der Aussagen in der Bedienungsanleitung braucht man auf dem entferneten Rechner (Network Connection) den Storage Manager nicht installieren. Dieses wohl nur, wenn man dort auch ein RAID zum kontrollieren hat. Es reicht ein normaler Browser mit der folgenden Adresse:
https://[IP-Adresse des Servers]:8443/maxview/manager/login.xhtml
Die Zugangsdaten sind die Linux Zugangsdaten des Admin-Users.
Hier kommt gleich das nächste Problem:
Der maxView-Storage-Manager läuft in einem Mode, in dem man nur sehen kann ohne dass man etwas einstellen kann. Um an das Menü zu kommen, in dem man den Standardmodus auch für normale Nutzer freischaltet, braucht man aber Adminrechte (sudo – gibt es in dieser Umgebung nicht). Deshalb muss man bei Ubuntu einmal Root freischalten, dann mit Root und dem Root-Passwort sich bei maxView anmelden, den Standardmodus auch für normale Benutzer freischalten (System-System Settings), Root wieder in Ubuntu löschen und sich dann als normaler Ubuntu-Admin bei maxView wieder anmelden. Ein schöner Rundtrip.
Als erstes habe ich dann die Systemsoftware des RAID-Controllers auf den neuesten Stand gebracht.
Danach sollte der RAID-Controller laufen und man Zugang zu den Einstellungen über den maxView-Storage-Manager haben.
Geschafft!
Ein RAID einrichten
Welchen RAID-Level, warum und wieso, dazu findet man jede Menge Literatur. Hier geht es um die konkrete Ausführung mit dem 81605ZQ-RAID-Controller von Adaptec.
Die oberste Ebene ist der Server, danach kommt der Controller und unter der Controller-Ebene braucht man jetzt ein „Logical Device“ also die logische Ebene die angesprochen wird.
- Server
- Controller
- logical device, dies ist mein RAID
- physical devices mit: 4 Connectors und an jedem Connector hängen 4 Festplatten
Ich habe RAID 6 genommen, da ich schon in der Testphase einen Festplattenausfall hatte und bei RAID 6 gleich 2 Platten auf einmal ausfallen können. Rein theoretisch müssten es somit 42 TB nutzbarer Speicher sein während man bei RAID 5 auf theoretische 45 TB kommt.
Da eine einzelne Platte aber in Wirklichkeit nur 2,729 TB hat kommt man auf folgende Werte:
44,67 TB gesamt
41,88 TB RAID 5
39,09 TB RAID 6 (maxView gibt an 39,059 TB)
Man klickt also auf „Controller“ und fügt ein „Logical Device“ hinzu. Dann wählt man „manuell“.
Hier noch ein paar Einstellungen die ich gewählt habe:
stripe size: 128 KByte (die Vorgabe 256 KB schien mir zu groß, trotz vieler Video-Dateien)
write cache: „enable write back“
read cache: „enable“
Was bedeutet das alles?
- stirpe size = kleinster zu beschreibender Platz, also auch eine kleinere Datei braucht diesen Platz – die Festplatten haben Blöcke mit 512 KB, es passen also in jeden Block bei mir 4 x 128KB Daten-Stripes
- write back = das RAID packt beim Schreiben alles in den Puffer und meldet an das Betriebssystem – alles geschrieben – schreibt aber erst später. Ist sehr schnell, aber nur mit Pufferbatterie zu empfehlen.
- write through = erst wenn tatsächlich geschrieben ist, wird auch „geschrieben“ gemeldet. Ist der größte Bremser bei Tests.
- read ahead = liest immer gleich schon mal auf Verdacht die Daten der Nachbarblöcke
- adaptive read ahead = nur wenn zwei Nachbarblöcke gelesen werden, liest der Controller auch weitere Blöcke auf Verdacht schon mal in den Puffer
- no read ahead
Detailwissen dazu findet man beim Tecchannel oder bei tom’s hardware.
TIPP:
Bevor man die Einrichtung abschließt ist es sinnvoll die Seriennummern der Festplatten aufzuschreiben und zu schauen, welche Platte laut maxView genau wo angebaut ist, so dass man bei Ausfällen nicht versehentlich die falsche Platte wechselt. Bei mir war in der Bedienungsanleitung die Connectorbezeichnung (Stecker für jeweils 4 Festplatten) falsch, dies kann schnell zu großen Verwechslungen führen!
Jetzt hat man also eine „nackte RAID-Festplatte“ mit 39,059 Millionen Megabyte oder mit 39 Tausend Gigabyte
Das hört sich sehr viel an, wenn man aber bedenkt, dass die dreitägigen Dreharbeiten für einen fünfminütigen Imagefilm, im normalen HD-Format, also nicht 4K oder dergleichen, mit allen Postproduktionsdateien ca. 1 Terabyte ausmachen, dann sind das gerade mal 39 Imagefilme die man mit diesem RAID produzieren kann. Also so eine Art „Berliner Flughafen“, der ja auch, falls er mal fertig werden wird, schon viel zu klein sein wird.
Energie sparen und Festplatten bei Nichtgebrauch herunterfahren
Über den maxView Storage Manager kann man festlegen, wann die Festplatten in den Ruhezustand gehen, falls für längere Zeit kein Zugriff erfolgt. Das Intervall sollte nicht zu kurz gewählt werden, da zu häufiges an und aus die Festplatten belastet.
Ich habe eine halbe Stunde gewählt, da dies meinem Arbeitsrhythmus entspricht. Wenn ich eine halbe Stunde nicht auf das Raid zugreife, dann habe ich die benötigten Daten heruntergeladen und arbeite wahrscheinlich gerade damit.
Einstellen kann man das Ganze auf der Ebene: „Controller-Logical Device-‚Device Name‘ “
Dann oben auf das „Ölfasssymbol“ klicken mit dem Zahnrädchen. Nach den Einstellungen für das Lese- und Schreibverhalten kommt man über den Reiter „Power“ auf das Stromsparmenü.
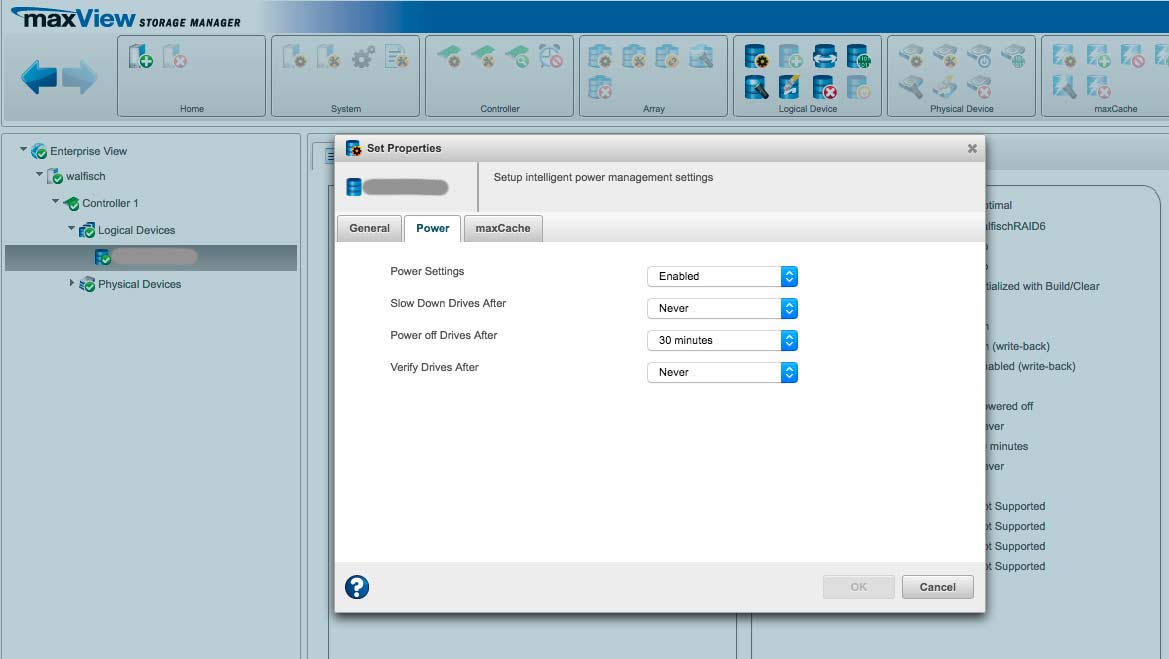
ACHTUNG FALLE
Beim Ruhezustand der Festplatten
Nachdem ich das Ganze so eingerichtet hatte, sind die Festplatten trotzdem nie in den Ruhezustand gegangen. Ich hatte die Vermutung, dass irgendeine Linux-Routine wahrscheinlich regelmässig auf das Raid zugreift und ein Herunterfahren verhindert. Hilfe brachte der Adaptec Support, der das Problem fand, nachdem ich ihm Logdateien zugeschickt hatte.
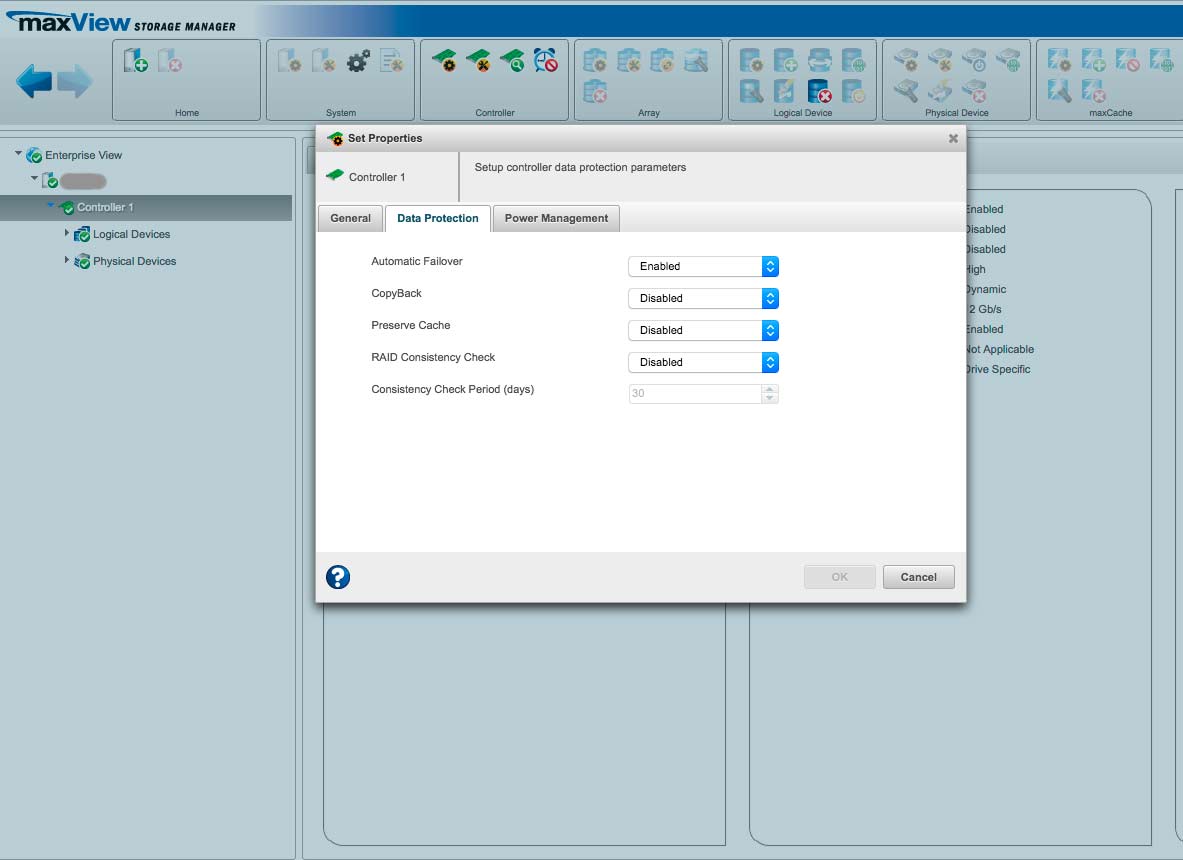
Die Funktion „Background Consistency Check“ hatte ich auf 42 Tage eingestellt. Dies bedeutet aber nicht, dass er alle 42 Tage checkt, sondern PERMANENT – „24/7“ wie es der Support nannte. Dies hat dann ein Herunterfahren verhindert. Ein sehr missverständliches Menü.
Den „Background Consistiency Check“ kann man unter der Rubrik: „Controller – Einstellungen – Data Protection – Raid Consistency Check“ ausschalten.
Will man die Datenkonsitenz regelmässig prüfen, dann gibt es folgenden Hinweis vom Support:
„Sie müssten dazu Ihr Array auswählen, dann unter der Logical Device Box auf Verify/Fix gehen und dann können Sie einen Verify with Fix planen (Schedule).“
Das RAID-System partionieren und ein Datensystem einrichten
Erst mal schauen, was wir so alles haben:
blkid -o list
Das RAID ist bei mir auf „/dev/sda“ unmounted zu finden.
Jetzt können wir es mit „parted“ partionieren:
parted /dev/sda
(parted) print
Wir sind jetzt innerhalb von (parted) und bekommen mit „print“ den Zustand:
Wir haben 39060 GiB (1 GiB = 2 hoch 30 Byte) zur Verfügung und die Sektorengröße beträgt 512 Bytes (also nicht wie bei SSDs 4 KByte-Sektoren).
Dann eine GUID-Partionstabelle GPT anlegen, denn wir wollen uns nicht mehr mit MBR-Beschränkungen plagen. „mklabel“ löscht alle Daten, da wir noch keine haben, kein Problem:
(parted) mklabel gpt
Wir haben es zwar mit Festplattensektoren mit 512 Bytes zu tun, wollen uns aber trotzdem an einem Vielfachen von 4 kByte ausrichten, also in dem Fall ein Vielfaches von 1 MiB (Mega-Byte zur Basis von 2). Deshalb stellen wir erst einmal parted auf MiB um und rechnen ab jetzt in MiB.
Am Anfang einer Festplatte wird immer 1 MiB freigelassen, das bezieht sich zwar nur auf Systemfestplatten, kann aber nicht schaden und wir haben ja genügend MiBs zur Verfügung. Dann schaut man, dass die Sektoren genau aneinander grenzen, und zwar genau mit den 1 MiB-Grenzen. Die eine hört bei 38.000.001 Mega-Byte auf und der nächste Sektor beginnt bei 38.000.02 Mega-Byte.
(parted) unit MiB
(parted) print
Unser RAID hat laut print-Ausgabe: /dev/sda 39 997 430 MiB.
Für die erste Partion lassen wir am Anfang 1 MiB frei und dann geht es so weit nach hinten, dass wir am Ende genau 38 TB also 38.000.000 MiB Platz in der ersten Partion haben, die wir „partionP1“ nennen.
Die zweite Zahl muss um 1 höher sein als die 38 000 000, da uns am Anfang ja 1 MiB fehlt:
(parted) mkpart partionP1 1MiB 38000001MiB
Die nächste Partion beginnt dann genau über der ersten Partion ( 380 … 02) und ganz am Ende habe ich nochmals 1 MiB Platz gelassen (Gesamt-MiB-Zahl minus 1), wer weiß für was es gut ist. Die zweite Partion habe ich „partionPS“ genannt, das sie später verschlüsselt wird:
(parted) mkpart partionPS 38000002MiB 1997427MiB
(parted) print
Nummer Anfang Ende Größe Dateisystem Name Flags
1 1,00MiB 38000001MiB 38000000MiB partionP1
2 38000002MiB 39997429MiB 1997427MiB partionPS
(parted) quit
Informationen: Möglicherweise müssen Sie /etc/fstab anpassen.
Parted ist ein freundliches Programm und sagt beim Abmelden, dass man /etc/fstab anpassen muss, damit das RAID beim Server-Start auch automatisch eingebunden wird. Doch erst einmal brauchen wir ein Dateisystem für beide Partionen. Dazu dient der Befehl „mkfs“.
Für den großen Speicher unserer ersten Partion, der auch viele Video-Dateien aufnehmen soll eignet sich am besten das xfs-Dateisystem, das seit Ubuntu 16.04 auch direkt vom Kernel unterstützt wird:
sudo mkfs.xfs /dev/sda1
Ausgabe:
meta-data=/dev/sda1 isize=512 agcount=37, agsize=268435455 blks
...............= sectsz=512 attr=2, projid32bit=1
...............= crc=1 finobt=1, sparse=0
data........= bsize=4096 blocks=9728000000, imaxpct=5
...............= sunit=0 swidth=0 blks
naming........ =version 2 bsize=4096 ascii-ci=0 ftype=1
log........... =Internes Protokoll bsize=4096 blocks=521728, version=2
...............= sectsz=512 sunit=0 blks, lazy-count=1
realtime.......=keine extsz=4096 blocks=0, rtextents=0
Bei jedem Mountvorgang wird das Dateisystem bei xfs überprüft. Um es manuell zu überprüfen, muss man es „umount-en“ (der Befehl ist immer ohne „n“ nach dem „u“ also „umount“) und dann mit „xfs_check“ überprüfen und gegebenenfalls mit „xfs_repair“ versuchen zu reparieren.
Die erste Partion unseres RAIDs mounten:
-t bedeutet Type und der ist „xfs“
Als Mountpunkt nehmen wir das Verzeichnis /srv, das Daten von Systemdiensten enthalten soll (FTP, SMB etc.):
sudo mount -t xfs /dev/sda1 /srv
prüfen:
df -h
ergibt in der letzten Zeile, der gemounteten Dateisysteme:
/dev/sda1 37T 34M 37T 1% /srv
Mountpunkte und Verzeichnisse
- /srv = „Service“, nehmen wir für unseren Samba-Server, dort einen Unterordner für den Fileserver: „/srv/fServer“
- /mnt = hier hängen wir die verschlüsselte Partion unseres RAIDs ein
- /var = hier liegen Dateien von E-Mail-Server, der Nachrichten bei Störungen verschickt
Verschlüsselung LUKS auf die Partion /dev/sda2 anwenden
Da wir eine sehr große Partion haben und eine kleine (knapp 2 TB) wollen wir die kleine Partion verschlüsseln. Schließlich hat man immer irgendwelche Daten, die man nicht die nächsten 100 Jahre bei der NSA, bei Prism, bei den Russen, Chinesen oder gar bei Google wiederfinden möchte.
Eine sehr ausführliche Anleitung zur recht „machtvollen“ Verschlüsselung von „LUKS“ findet man im Linux-Magazin 08/2005.
Das Projekt „LUKS“ ist dabei eine Weiterentwicklung von „Cryptsetup“.
Es sind verschiedene Schritte durchzuführen:
a. „cryptsetup“ mit „luksFormat“ und verschiedenen Variablen
-c bestimmt den Algorithmus („aes-cbc-essiv“ soll sehr gut sein)
-y bestimmt, dass die Passphrase zweimal eingegeben werden muss, am besten vorher schon einen schönen Satz ausdenken, den man sich auch merken kann
-s die Länge des Verschlüsselungsschlüssels, 128 oder 256
sudo cryptsetup -c aes-cbc-essiv:sha256 -y -s 256 luksFormat /dev/sda2
b. Mit „luksOpen“ einen virtuellen Namen und ein mapping erstellen
Dann weist man mit „luksOpen“ dem virtuellen verschlüsselten Laufwerk einen Namen zu (mapping). Hier als Beispiel: „meinLukusOrdner“. Dieser wird mit dem realen Laufwerk „/dev/sda2“ verknüpft. Dabei muss man muss die Passphrase angeben.
sudo cryptsetup luksOpen /dev/sda2 meinLukusOrdner
c. Dateisystem für das verschlüsselte Laufwerk erstellen
Nun ist das verschlüsselte virtuelle Laufwerk unter „/dev/mapper/meinLukusOrdner“ zu finden und braucht noch ein Dateisystem („xfs“). Danach bekommt man etliche Ausgaben:
sudo mkfs.xfs /dev/mapper/meinLukusOrdner
meta-data=/dev/mapper/meinLukusOrdner isize=512 agcount=4, agsize=127835200 blks
.........= sectsz=512 attr=2, projid32bit=1
.........= crc=1 finobt=1, sparse=0
data.....= bsize=4096 blocks=511340800, imaxpct=5
.........= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =Internes Protokoll bsize=4096 blocks=249678, version=2
.........= sectsz=512 sunit=0 blks, lazy-count=1
realtime =keine extsz=4096 blocks=0, rtextents=0
d. mounten
Jetzt kann man das neue virtuelle, verschlüsselte Laufwerk mounten.
In meinem Beispiel an „/mnt“ :
sudo mount /dev/mapper/meinLukusOrdner /mnt
e. wieder verschließen, nicht nur „umount“
Das Ganze wieder verschließen, erst „umount“ und dann „luksClose“, das das Verzeichnis wirklich wieder abschließt! Ansonsten kann man ohne Passphrase wieder mounten.
sudo umount /mnt
sudo cryptsetup luksClose meinLukusOrdner
f. So bekommt man das verschlüsselte Laufwerk wieder aktiviert
sudo cryptsetup luksOpen /dev/sda2 meinLukusOrdner
Geben Sie die Passphrase für »/dev/sda2« ein:
sudo mount /dev/mapper/meinLukusOrdner /mnt
Fertig!
Man kann das Passwort auch in einer Datei liefern oder mehrere Passwörter hinzufügen, so dass mehrere Menschen mit unterschiedlichen Passwörtern auf das Verzeichnis zugreifen können. Ist ein Passwort kompromittiert, so kann man es löschen und durch ein neues ersetzen. Es gehen bis zu 8 Passwörter.
Neues Passwort hinzufügen:
cryptsetup luksAddKey /dev/sda2
Passwort löschen, wobei am Ende der Slot steht in dem der Key sich befindet, hier die „0“:
cryptsetup luksDelKey /dev/sda2 0
Crypto Metainformationen gibt es mit „luksDump“, hier werden auch die „Key-Slots“ angezeigt, nur welcher welcher ist kann man hier auch nicht sagen. Eigentlich sollte bei jeder Passwort-Eingabe auch dessen „Key-Slot“ (also seine Platznummer, um das Passwort zu identifizieren, da man es ja nicht lesen kann) angezeigt werden, aber vielleicht geschieht dies erst, wenn man mehr als nur ein Schlüsselwort hat.
cryptsetup luksDump /dev/sda2
Mehr im Linux-Magazin 08/2005 zur LUKS-Verschlüsselung.
Wie sicher welche Verschlüsselungstechnik ist zeigt das Linux-Magazin 10/2006.
Bei meinem Fileserver muss ich natürlich immer die Partion aufschließen und nach dem Benutzen wieder verschließen. Da dort aber nur wirklich persönliche Dinge gespeichert werden, ist dies nicht problematisch. Dass bei einem automatischen Server-Neustart in Abwesenheit, die private Partion zu bleibt ist auch zu verkraften.
Der normale Bereich (/dev/sda1 und das Linux-System) wird ja ebenfalls nach außen durch Passwörter geschützt, ist also nicht direkt zugänglich nur eben nicht verschlüsselt.
Beim Systemstart die Laufwerke einbinden mit /etc/fstab
Die Datei fstab sorgt dafür, dass Laufwerke gleich zu Beginn des Serverstarts auch gemountet werden. Für die systemrelevanten Laufwerke ist dies selbstverständlich und wird bei der Einrichtung berücksichtigt, für unser RAID müssen wir das händisch nachtragen:
Bevor wir beginnen brauchen wir die internen Bezeichnungsnummern (UUID) der Partionen bzw. Festplatten:
blkid
liefert
/dev/sda1: UUID="xxxxxxxx-xxxxxxxxx-xxxxxxxx" TYPE="xfs" PARTLABEL="RaidpartionZazu" PARTUUID="yyyyyyy-yyyyyyyy-yyyyy-yyyyyyy"
fstab öffnen mit vim
sudo vim /etc/fstab
dann die /dev/sda1 mit ihrer UUID angeben den gewünschten Einhängepunkt und ein paar Optionen / die Zwischenräume sind Tabulatoren:
UUID=xxxxxxxx-xxxxxxxxx-xxxxxxxx /srv/fServer xfs defaults 0 0
zur Erklärung:
- Spalte 1 = UUID-Nummer der Partion /dev/sda1
- Spalte 2 = Einhängepunkt
- Spalte 3 = Dateisystem
- Spalte 4 = Optionen für den Zugriff auf den Datenträger (hier „defaults“)
- Spalte 5 = wird von Linux ignoriert deshalb „0“
- Spalte 6 = in welcher Reihenfolge beim Systemstart zu überprüfen / Systempartion bekommt „1“ alle anderen „0“
Mit „ESC“ raus aus dem Schreibmodus und mit „:qw“ speichern, dann „reboot“.
Die verschlüsselte Partion beim Systemstart einbinden?
Dies bedeutet, dass bei jedem Systemstart, direkt am Terminal des Servers die Passphrase angegeben werden muss, ansonsten bootet das Server-System nicht.
Das ist eher lästig, da man immer einen Bildschirm und eine Tastatur am Server haben muss. Wer das dennoch will findet eine gute Anleitung zum Einbinden einer verschlüsselten Partion in der Linux-Community.
Achtung:
Hier muss mit den „gemappten Namen“ gearbeitet werden die UUID hat bei mir nicht funktioniert, bzw. der Server hat in den Notmodus gebootet. Man braucht zwei Einträge, einmal in die „/etc/crypttab“ und einmal in die „/etc/fstab„:
sudo vim /etc/crypttab
meinLukusOrdner /dev/sda2 none luks,check=xfs
sudo vim /etc/fstab
/dev/mapper/meinLukusOrdner /mnt auto defaults 1 1
Danach kommt beim Serverstart eine Aufforderung zur Eingabe der Passphrase. Anschließend wird die Partion gemountet.
VI. Samba Server Datenaustausch mit dem „smb-Protokoll“
smb ist ein Protokoll zum Datenaustausch, das bisher hauptsächlich auf Windows eingesetzt wurde. Ziel ist es ein entferntes Verzeichnis wie eine am Computer angeschlossene Festplatte zu behandeln.
Der Mac und Linux konnten zwar bisher auch mit smb kommunizieren, haben aber noch ihre eigenen Protokolle. Für den Mac ist es das AFP-Apple Filing Protocol und für Linux das klassische Unix-Protokoll NFS-Network File System. Apple setzt seit einiger Zeit ebenfalls vermehrt auf das smb-Protokoll, so dass dies momentan die beste Austauschplattform für alle Systeme bietet.
Samba besteht aus zwei Prozessen, einmal der nmbd-Prozess für die interne Verwaltung, Namensverwaltung und das Browsing um zu schauen, welche zugänglichen Verzeichnisse im Netz sind und den smbd-Prozess, der die Schnittstelle für Clients bereitstellt.
Samba-Server Config-Datei
Die zentrale Verwaltungsdatei für den smb-Server liegt unter:
/etc/samba/smb.conf
Zuerst kopieren wir die Datei, damit man immer nachschauen, was im Original für Standardwerte enthalten waren. Die „Archiv-Datei“ heißt dann cmb.conf.orig
sudo cp smb.conf smb.conf.orig
Samba-Server Passwörter und User-Level-Sicherheit
Samba hat verschiedene Sicherheitskonzepte. Bei kleineren Installationen wird in der Regel „User-Level-Sicherheit“ implementiert:
Wichtig:
Wenn Anwender A auf Rechner A Daten vom Samba-Server S abrufen will, dann muss er sowohl auf Rechner A als auch auf Samba-Server S mit dem gleichen Namen und Passwort registriert sein. Darüber hinaus müssen beide Rechner zur selben Arbeitsgruppe gehören! Nur dann kann man ohne Passworteingabe zugreifen.
Stimmen die Passwörter zwischen Samba und lokalem Rechner nicht überein erscheint jedes Mal eine Dialogbox mit der Samba-Username und Samba-Passwort Aufforderung.
Nur ein registrierter Linux-User kann den Linux-Samba-Server nutzen! Deshalb ist es sinnvoll für User die mit dem Linux-Server sonst nichts zu tun haben den Linux-Account mit „lock = -l“ zu sperren:
passwd -l [userName]
Samba verwaltet seine Passwörter separat, weshalb sie auch verschieden sein können von den Linux-User-Passwörtern. Beide zu synchronisieren ist mit Hilfe von „pam password change“ möglich und auch in der Konfigurationsdatei von Samba schon vorgesehen. Dabei wird bei jedem Ändern des Samba-Passwortes auch das Linux-Passwort geändert. Dies geht aber nur, wenn man auch als eigener Benutzer angemeldet ist, also nicht von Root! Deshalb ist bei einer kleinen Umgebung mit wenigen Nutzern es sicher ausreichend, wenn man dies von Hand erledigt, also Samba-Passwort ändern und Linux-User-Passwort ändern, so dass man immer nur ein Passwort hat für beide Prozesse. Um die Synchronisation auszuschalten schreibt man in der smb.con:
unix password sync = no
In unserem Fall ist eine Synchronisation sowieso nicht notwendig, da der Ubuntu-Linux-Server-User nichts mit Samba zu tun hat, sondern nur den Server verwaltet. Für Samba werden eigene User angelegt, die den Server aber nicht verwalten können.
Samba einrichten
Eine gute Beschreibung gibt es auch von Michael Kofler: Linux – Das umfassende Handbuch, eine schlechte Beschreibung liefert leider: Praxisbuch Ubuntu Server 14.04 LTS von Charly Kühnast und Daniel van Soest, hier wird das Thema nur gestreift.
Samba-User anlegen
Wir erstellen eine Minimaleinrichtung (kiss = keep it simple stupid), es gibt zwei User, die damit automatisch auch eine Gruppe besitzen mit demselben Namen. Der eine User heißt „angestellter“ der andere „chef“. Beide haben keinen Zugang zum Server direkt, da sie ohne Passwörter angelegt werden.
sudo useradd angestellter
sudo useradd chef
Beide bekommen auch kein Homeverzeichnis ansonsten: „useradd -m chef“
Auf dem Ubuntu-Server sind somit folgende User angelegt:
- Root = deaktiviert (immer bei Ubuntu)
- XXXXX = Ihr User mit dem Sie den Server verwalten, hat vollen Linux-Zugang und kann über „sudo“ sich wie „root“ verhalten
- chef = Sie selbst, wird für Samba benutzt, kein Linux-Zugang
- angestellter = sonstiger Samba-Nutzer, kein Linux-Zugang
Damit haben Sie eine klare Trennung zwischen Server-Verwaltung und Samba-Nutzung.
Nun bekommen die beiden User ein Samba-Passwort:
sudo smbpasswd -a angestellter
sudo smbpasswd -a chef
Alle vorhandenen User anzeigen:
Will man sich anzeigen lassen, was für User es auf dem System gibt, dann schaut man z. B. mit dem Programm vim in die Datei /etc/passwd.
Zuordnung zwischen lokalem Rechner Benutzernamen und Linux-(Samba)-Benutzernamen
Will man nicht jedes Mal, wenn man auf den Samba-Server zugreift, ein Passwort eingeben oder auch nicht das Passwort z. B. beim Mac im Schlüsselbund speichern, dann müssen die Passwörter auf dem lokalen Rechner, an dem man arbeitet und das Samba-Passwort übereinstimmen. Die Nutzernamen können aber mit Hilfe einer Datei zugeordnet werden. Heißt mein Account auf meinem Windows- oder Mac-Rechner „Thomas Hezel“ und mein Samba-Account „chef“, dann wird er zugeordnet, indem man die folgende Zeile in die Datei „smbusers“ schreibt. Hierfür kann man wieder „vim“ benutzen. Die smbusers-Datei hat bei meiner Ubuntu-Installation jedoch noch gar nicht existiert.
# /etc/samba/smbusers
chef = "Thomas Hezel"
ACHTUNG GEFAHR
Wenn jemand in dieser Datei „root“ einem entfernten Benutzer zuordnet oder Ihren Verwaltungsaccount sich selbst, dann besteht eine große Sicherheitslücke, deshalb die Datei „smbusers“ sorgsam ausfüllen und ihr entsprechende Rechte geben, so dass nur Root schreiben darf.
chmod 644 /etc/samba/smbusers
In der Samba-Einstellungsdatei „smb.conf“ muss dann noch die Zuordnungsdatei registriert werden:
# /etc/samba/smb.conf
[global]
…
username map = /etc/samba/smbusers
Ordner anlegen und Rechte einstellen
Wir erstellen auf unserem Dateisystem jeweils einen Ordner für die Firma mit dem Namen „Firma“ und einen zu dem nur der Chef Zugang hat „Chef“.
Anmerkung:
Zu Usern zugehörige Ordner werden, wie bei TYPO3, mit großem Anfangsbuchstagen geschrieben.
Der Ort ist natürlich die große Partion auf unserm RAID 6: /dev/sda1
Dieses mounten und dann die Ordner erstellen, diesen Ordner die jeweilige Gruppe zuordnen (Ordner „Chef“ bekommt die Gruppe „chef“) und die Rechte auf 770 stellen, also Owner und Group dürfen lesen, schreiben und ausführen, der Rest hat keine Rechte „0“.
Ordner „Firma“ bekommt die Gruppe „angestellter“ und die Rechte 770.
Der verschlüsselte Bereich auf /dev/sda2 bekommt einen Ordner mit dem Namen „Sicher“, dieser bekommt die Rechte 770 und den Owner „chef“.
Dann fügen wir noch den „chef“ zur Gruppe „angestellter“ hinzu, so dass der Chef auch den Ordner für die Angestellten nutzen kann.
sudo usermod -aG angestellter chef
Und unser Linux-Administrator soll ja auch in die Ordner reinschauen können, also kommt dieser sowohl zur Gruppe „chef“ als auch zu Gruppe „angestellter“:
sudo usermod -aG angestellter xxx-linux-admin
sudo usermod -aG chef chef xxx-linux-admin
Achtung Gruppe-User Verwirrung:
Wenn man einen User Hans anlegt, dann entsteht automatisch auch die Gruppe Hans. Somit ist es möglich, dass User Lisa sich der Gruppe Hans anschließt und dann die Rechte bekommt, die für die Gruppe Hans eingestellt sind.
Wer ist nun in welcher Gruppe?
Diese Frage beantwortet ein Blick in die „group-Datei“:
sudo vim /etc/group
Zentrale Einstellungsdatei für den Samba-Server unter /etc/samba/smb.conf
Unter Linux gilt die Unix-Regel: „Alles ist eine Datei.“
Also sind auch alle Einstellungen, die man macht, in Dateien hinterlegt. In diesem Fall in „smb.conf“.
Zum Bearbeiten benutzt man einen Linux-Editor, also ein Programm, das Textdateien bearbeiten kann. Die bekanntesten sind „vim“ und „nano“. Ich benutze meist „vim“.
Die wichtigsten Kommandos bei „vim“ sind:
- a = man kommt in den insert-Schreibmodus
- esc-Taste = man kommt aus dem Schreibmodus heraus
- :/ Suchbegriff = suchen
- :q = quit ohne speichern (falls man Veränderungen gemacht hat, diese aber nicht speichern will heißt der Befehl „:q!“)
- :wq = write and quit (also speichern und schließen)
Wenn man die obigen Kommandos beherrscht, hat man quasi schon einen Linux-Bachelor-Abschluss.
Eine sehr gute und „persönliche“ – man fühlt sich wie damals in der Grundschule – Einführung in Linux gibt „Eli the Computer Guy“ in seinen Videos.
/etc/samba/smb.conf bearbeiten
Falls wir Unfug machen, erstellen wir erst mal eine Kopie der Datei, auf die wir in der Not zurückgreifen können:
sudo cp smb.conf smb.conf.orig
Einstellungsdatei smb.conf öffnen:
sudo vim smb.conf
Einstellungen vornehmen
workgroup = ZAZU
server string = [default]
wins support = yes
#wins support = yes, bedeutet ich agiere als wins-Server
# wins server =
#auskommentiert, da dies bedeutet ein Client zu sein, der Server aber schon ein wins-Server ist
dns proxy = yes
#samba soll auf DNS-Einträge vom Router zurückgreifen
unix password sync = no
#kein Abgleich zwischen Linux und Samba Passwörtern
map to guest = never
#keine Gäste zulassen
usershare allow guests = no
#nein Gäste sollen keine Verzeichnisse erstellen können
unter Share Definition:
[Firma]
valid users = @angestellter,@chef
path = /srv/smb/Firma
writeable = yes
public = no
guest ok = no
force group = +angestellter
create mask = 0660
directory mask = 0770
[Chef]
valid users = @chef
path = /srv/smb/Chef
writeable = yes
public = no
guest ok = no
force group = +chef
create mask = 0660
directory mask = 0770
[Secure]
valid users = @chef
path = /mnt/Secure
writeable = yes
public = no
guest ok = no<
force group = +chef
create mask = 0660
directory mask = 0770
public = no / bedeutet, dass man nur als registrierter Nutzer zugreifen kann
guest ok = no / keine Gäste, im Grunde dasselbe wie Public
force group = +chef / neue Dateien bekommen die Gruppe Chef
create mask = 0660 / neue Dateien bekommen die Rechte 660, lesen und schreiben für den Owner und die Gruppe
directory mask = 0770 / neue Ordner bekommen die Rechte 770, lesen, schreiben und ausführen für den Owner und die Gruppe
ACHTUNG
Unbedingt bei „force group“ auf das „+“ achten, ohne das Plus bedeutet es, dass jeder Zugriff, als ein Zugriff von dieser Gruppe gewertet wird. Dies ist ein Sicherheitsproblem!
Dann mit „ESC“ raus aus dem Schreibmodus und mit „:wq“ speichern.
Habe ich alles Richtig gemacht?
Prüfen mit
/etc/smb/ testparm
Es kommt bei mir:
WARNING: The "syslog" option is deprecated
Diese kann man auskommentieren.
syslog = 0 bedeutet eigentlich, dass nur Fehler protokolliert werden nicht Warnungen etc.
Jetzt muss der Samba-Service neu gestartet werden, damit die Änderungen eingelesen werden:
service samba reload
Änderungen, damit Samba als wins-server auftritt – FUNKTIONIERT BEI MIR NICHT
Bei mir geht nach der festen Vergabe von IP-Adressen das Browsing nicht mehr, d. h. ich sehe nicht mehr auf meinen Clients automatisch die smb-Freigaben, sondern muss mich immer per Kommando mit dem Server verbinden (Mac: „Mit Server verbinden …“). Mehr zu Browsing-List-Fähigkeiten gibt es bei Linux-Praxis, der folgende Korrekturen vorschlägt, die bei mir aber auch nichts genutzt haben. Wichtg ist wohl, dass es einen „guest account“ gibt, da das Browsing über diesen abgewickelt wird:
#neu Samba als localer wins-server, braucht guest account
wins server = xxx.xxx.xxx.xx #ist dies die eigene ip-Adresse?
guest account = nobody
local master = yes
preferred master = yes
os level = 65
map to guest = bad user
Auch diese Einstellung bringt keine Änderung. Der Name des Servers taucht NICHT automatisch im Finder des Mac auf. Ein Zugang zum Samba-Server muss immer über das Menü „Gehe zu – Mit Server verbinden …“ und der IP-Adresse eingeleitet werden.
Einen Papierkorb einrichten
Normalerweise sind bei Samba gelöschte Dateien einfach gelöscht. Es gibt nicht die Papierkorbfunktion. Ubuntu-Users gibt eine Anleitung, wie man dies jedoch mit Hilfe eines versteckten Ordners, „.recylcebin“ realisieren kann. Der Ordner muss dann von Zeit zu Zeit manuell gelöscht werden. Er wird bei der ersten Löschung automatisch eingerichtet. Die Angaben kommen in den allgemeinen Bereich, damit sie für alle Shares gelten:
# Ein Papierkorb wird eingerichtet:
vfs object = recycle
# Der Pfad zum Papierkorb relativ zur Freigabe (".recyclebin" ist Default).
recycle:repository = .recyclebin
# Im Papierkorb bleiben Pfad-Angaben erhalten.
recycle:keeptree = Yes
# Beim Verschieben wird der Zeitstempel angepasst.
recycle:touch = Yes
# Gleichnamige Dateien werden nicht überschrieben.
recycle:versions = Yes
# Keine Begrenzung der Dateigröße.
recycle:maxsize = 0
Die Einstellung gilt, wenn sie über den Shares steht, für alle Shares. In jedem Share entsteht der Ordner „.recyclebin“ und in diesem Ordner werden die Original-Ordner wieder hergestellt in denen die Datei lag, die gelöscht wurde. Liegt die gelöschte Datei in Ordner B und dieser in Ordner A so sind die beiden Ordner A+B und die Datei auch im „.recyclebin“ vorhanden.
Nur man darf das Löschen nicht vergessen, sonst frisst der Papierkorb irgendwann sehr viel Platz.
Zugriff auf den Samba-Server
Wichtig ist, dass auf dem entfernten Rechner die richtige „WORKGROUP“ eingestellt wird (anscheinend schreibt man die immer in Großbuchstaben). Voreingestellt ist meist „WORKGROUP“, das müssen wir in unserem Fall auf dem entfernten Rechner in „ZAZU“ ändern!
Beim Mac ist dies unter:
Systemeinstellungen–Netzwerk–Ethernet–Weitere Optionen–WINS
Dann kann man darunter noch die IP-Adresse unseres WINS-Servers (Samba-Servers) eintragen.
Zugriff von einem Mac aus
Falls der Server nicht unter den Festplatten im Findermenü links erscheint (was manchmal mit DHCP automatisch klappt), kann man im Finder-Menü über:
Gehe zu – Mit Server verbinden …
entweder auf „Durchsuchen“ gehen oder oben „smb://[IP-Adresse-Server / oder Servernamen]“ eine Verbindung herstellen. Da die Passwörter und Namen des entfernten Rechners bei mir nicht übereinstimmen muss man diese jetzt angeben. Gegebenenfalls kann man die Zugangsdaten jetzt auch im Schlüsselbund des Macs speichern. Danach öffnet sich ein Fenster mit dem ausgewählten Ordner des Samba-Servers.
Manchmal findet der Mac den vorhandenen Samba-Server auch von alleine und bietet ihn unter „Freigaben“ oder „Netzwerk“ im Findermenü direkt an. Das Einloggen bleibt aber das Gleiche. Will man nicht das Passwort im Schlüsselbund speichern und sich direkt einloggen, so müssen die Benutzernamen vom Mac und vom Samba-Server „gemappt“ werden (siehe oben) und die Passwörter müssen identisch sein.
Zugriff vom Ubuntu-Desktop
Auf das Aktenschranksymbol links klicken, „Mit Server verbinden“ auswählen „smb://[IP-Adresse-Server]“ eingeben und einloggen.
Zugriff von Windows 7 aus
Man muss den alten Internet-Explorer herauskramen und dort in der Pfadleiste eingeben:
\\[server-name oder ip-adresse]
Hier sind die „Rückstriche/Backslashes“ wichtig, die man über „AltGr+ß“ erreicht.
Dann öffnet sich ein Fenster und man kann sich mit Samba-User-Namen und Passwort verbinden. Es erschienen alle „Freigaben“ und man kann diejenigen für die der Name und das Passwort gilt anklicken und dann nutzten.
Bei mir war noch unter „Computer-Rechtsklick-Erweiterte Systemeinstellungen-Computername-Netzwerk-ID-Ändern …“ die Standard „WORKGROUP“ eingestellt, die ich auf „ZAZU“ geändert habe.
Zum Schluss Samba-Server absichern
(siehe dazu auch nächstes Kapitel)
Auf alle Fälle sollte die Firewall auf dem Router zu sein (TCP Ports: 135, 139, 445 und UDP-Ports 137, 138 und 445), damit man gegenüber dem Internet abgesichert ist. Samba ist für den Betrieb im Internet nicht geeignet!
Innerhalb des eigenen Netzwerks kann man noch den Zugang auf bestimmte Rechner oder IP-Adressen beschränken:
# /etc/samba/smb.cnf
[gobal]
bind interfaces only = yes
interfaces = [IP-Adresse],[IP-Adresse]
hosts allow = RechnerA RechnerB
map to guest = never
VII. Sicherheitsmaßnahmen für Samba und SSH
fail2ban für den Samba-Server – Kampf gegen Verschlüsselungserpressung
Man kann fail2ban, das im nächsten Abschnitt (openSSH) beschrieben wird, auch benutzen um bestimmte Dateien oder Dateiänderungen innerhalb von Samba zu unterbinden. Der User wird einfach ausgeloggt, bevor er länger Zeit hat um z. B. ein Verzeichnis zu verschlüsseln, damit der Besitzer später erpresst werden kann („Locky“).
Heise Security hat ein Ablauf entwickelt mit dem man fail2ban für Samba einsetzen kann. Eine gute Liste von Dateinamen und Endungen, die von Locky-Erpressern benutzt werden gibt es bei univention. Wie man die Portokollierung bei Samba auf Dateien bezieht findet man in Martin’s Blog.
Manche Dateien (samba.conf einmal unter „/etc/fail2ban/filter.d/“ und einmal unter „/etc/fail2ban/jail.d/“) muss man auch mit sudo touch anlegen, das ist bei Heise nicht sehr gut beschrieben. Die Logdateien landen im /var/log/syslog.
Achtung:
Bei meiner Konfiguration (siehe unter fail2ban und ssh) benutze ich „jail.local“ anstelle von „jail.conf“!
openSSH-Server absichern
SSH bietet direkten Zugang zum Server und dies auch aus dem Internet, vorausgesetzt im Router hat die Firewall den entsprechenden Port offen. Hat jemand Zugang zu SSH, dann hat er auch Zugang zum gesamten Server. Dies muss man verhindern.
Alles was auf dem Server passiert wird in den Log-Dateien vermerkt, also auch Angriffsversuche:
sudo vim /var/log/auth.log
Folgende Maßnahmen kann man treffen:
- den Port ändern
- root aussperren
- alle Passwörter verschlüsselt?
- nach zu vielen Fehlversuchen eine Zwangspause einlegen mit fail2ban
- Sicherheitskonzept erhöhen mit Schlüsseln und Passwort
a. Den SSH-Port ändern
SSH-läuft standardmäßig auf Port 22, ändert man diesen z. B. auf Port 666, dann muss der Angreifer erst einen Portscan machen, bevor er überhaupt an den SSH-Server kommt. Nicht unmöglich, aber eine Hürde für automatisierte Angriffe:
sudo vim /etc/ssh/sshd_config
Port 666
Ganz oben den alten Eintrag auskommentieren und den neuen einfügen.
b. Root aus SSH aussperren
Sollte Root aktiviert sein (bei Ubuntu ausgeschaltet), dann muss ein Angreifer nur das Passwort von Root erraten, deshalb Root am Besten gleich für SSH deaktivieren. Der Defaultwert ist „prohibit-passwort“, was bedeutet Root darf nur mit einem Schlüssel aber nicht mit einem Passwort zugreifen. Ändern in sshd_config:
PermitRootLogin no
# zum speichern
ESC-Taste
:wq
c. Alle Benutzerpasswörter müssen verschlüsselt gespeichert sein
Die Datei in der man das sieht ist: /etc/shadow
Hier sollten für alle User, die ein Passwort besitzen, zwischen den ersten beiden Doppelpunkten eine lange Zeichenketten sein. Bei System-Accounts ist es ein Stern oder eine Ausrufezeichen. Falls es Benutzer gibt, die ein Passwort haben aber keine Verschlüsselungskette sollten Sie ihnen sofort ein Passwort geben:
sudo password [Name]
d. Fail2Ban oder Pause nach zu vielen Versuchen bei ssh
Das Programm kann alle möglichen Netzwerkdienste überwachen und erstellt Firewall-Regeln, nachdem es zu viele Fehlversuche entdeckt hat.
sudo apt-get update
sudo apt-get install fail2ban
Die Eistellungsdatei finden wir in: „/etc/fail2ban/“ – dort ist es die Datei: „jail.conf“
Diese Datei kopieren wir als jail.local, die dann den Vorrang hat. So erhalten wir die alte Datei mit den Default-Werten, falls wir wieder zurück müssen und etwas schief gelaufen ist.
sudo cd /etc/fail2ban
sudo cp jail.conf jail.local
Nun ändern wir die jail.local-Datei:
enable = true einfügen:
[sshd]
port = ssh
logpath = %(sshd_log)s
enable = true
Die Werte am Anfang der Datei sagen aus, dass 10 Minuten gesperrt wird, wer innerhalb von 10 Minuten 5 Fehlversuche gestartet hat. Dies Werte kann man global oder nur durch Eintrag im [sshd-Block] ändern:
# "bantime" is the number of seconds that a host is banned.
bantime = 600
# A host is banned if it has generated „maxretry“ during the last „findtime“
# seconds.
findtime = 600
# „maxretry“ is the number of failures before a host get banned.
maxretry = 5
Dann alles speichern und den Prozess starten:
sudo systemctl restart fail2ban
sudo systemctl enable fail2ban
Zustand kontrollieren:
sudo fail2ban-client status sshd
Status for the jail: sshd
|- Filter
| |- Currently failed: 0
| |- Total failed: 0
| `- File list: /var/log/auth.log
`- Actions
|- Currently banned: 0
|- Total banned: 0
`- Banned IP list:
Eine sehr gute, erweiterte Anleitung zu fail2ban und openSSh, finden Sie bei DigitalOcean.
e. SSH mit Schlüsseln plus Passwort betreiben
Anleitungen finden sich im Internet und im Kofler-Linux-Buch. Da ich unterschiedliche Rechner nutze, um mich einzuloggen, müsste ich immer den Schlüssel dabei haben und auf dem jeweiligen Rechner installiern. Das ist mir zu umständlich.
VIII. sFTP-Server mit openSSH-Server realisieren / teilweise
Man kann mit dem Administrator und seinem Passwort ganz normal z. B. über das Programm „Transmit“ und der Einstellung „sFTP“ auf den kompletten Server zugreifen. Schön wäre es jedoch, dass man den Zugang auf einzelne Verzeichnisse beschränken könnte, um einzelnen Usern so einen eingeschränkten Zugang zu ermöglichen. Damit hätte man eine sichere SSH-sFTP-Kommunikation und könnte sich die Einrichtung eines FTP-Servers sparen, denn mehr Server bedeutet ja auch immer mehr Zugänge und mehr Zugänge bedeutet weniger Sicherheit.
Aber will man Samba und sFTP kombinieren, dann macht es Sinn, dass die Ordner außerhalb von „/home“ liegen, nur scheint das nicht zu gehen:
Der Versuch einen Ordner der außerhalb von „/home“ liegt als „chroot“ (Gefängnis aus dem der eingeloogte sFTP-User nicht herraus kommt, um auf dem Server Unheil zu stiften) zu benutzen, um dort mit sFTP Inhalte abzulegen, hat nicht funktioniert. Anscheinend ist bei Ubuntu 16.10 hier irgendwo eine Sperre eingebaut (vielleicht appAmor).
Hier mein Vorgehen, falls noch jemand Tipps hat, bin ich dankbar für Anregungen!
Eine Anleitung für einen sFTP-Zugang mit chroot innerhalb von Home findet man z. B. bei „dann rate mal“ oder ausführlicher bei KaiRaven.
Sicherheitshalber die sshd_config duplizieren und das Original sichern und der Datei „sshd_config“ nur Schreibrechte für Root geben:
sudo cp sshd_config sshd_config.original
sudo chmod 640 /etc/ssh/sshd_config
Dann in der „sshd_config“ die Änderungen vornehmen:
sudo vim /etc/ssh/sshd_config
Subsystem auskommentieren und neue Subsystemzeile einfügen:
#Subsystem sftp /usr/lib/openssh/sftp-server
Subsystem sftp internal-sftp
Jetzt das „ChrootDirectory“ für den Nutzer einrichten:
#weiter sftp Einrichten zazu kunden
Match User kunden
ChrootDirectory /srv/Kunden
ForceCommand internal-sftp
AllowTcpForwarding no
PermitTunnel no
X11Forwarding no
Damit ist dieser Teil in der „sshd_config“ fertig. Wir legen, falls nicht vorhanden, den User „kunden“ an.
sudo adduser kunden
Verhindern, dass der User einen Shell-Zugang bekommt. Ein Shellzugang ist laut „man sshd_config“ bei sFTP nicht nötig:
sudo usermod -s /bin/false kunden
Im Ordner „srv/Kunden“ muss es „/srv/Kunden/home/“ und „/srv/Kunden/home/kunden/“ geben. Sie müssen alle „root“ gehören und kein anderer darf Schreibzugriff haben. Das Manual sagt:
man sshd_config
"ChrootDirecotry
Specifies the pathname of a directory to chroot(2) to after authentication. At session startup sshd(8) checks that all components of the pathname are root-owned directories which are not writable by any other user or group. After the chroot, sshd(8) changes the working directory to the user's home directory."
Das müsste bedeuten, dass nachdem man „ge-chroot-ed“ ist, das „chroot-dirctory“ der neue Wurzelpunkt ist und von da an leitet chroot in das „home-directory“ (innerhalb des „chroot-directory“ für den User.
Folglich muss in der /etc/passwd-Datei folgendes stehen:
test:x:1004:1008:,,,:/home/kunden:/bin/false
Siehe zum chroot-außerhalb von home auch den Artikel bei serverFault.
Jetzt den ssh-Server neu starten:
sudo /etc/init.d/ssh restart
Das funktioniert bei mir NICHT!
Solange ich mein „chroot-directory“ untehalb von „/home“ habe, also das reguläre Home-Verzeichnis des Users, geht alles prima und er kommt auch nicht aus seinem Home-Verzeichnis raus, also chroot funktioniert. Wenn aber mein Chroot-Ordner außerhalb von Home liegt geht das Ganze nicht.
Ideen? Anregungen?
IX. Netzwerk von DHCP auf feste IP-Adresse umstellen, LAN-Leitungen bündeln
Feste IP-Adressen für die Schnittstellen
Hat man mehr als einen Netzwerkadapter, dann kann man feststellen welche Controller es gibt. In der Regel sind die Intel-Controller am schnellsten:
lspci | grep -i net
Bei meinem Mainboard heißen die 10 Gb-Schnittstellen „rename 4“ und „rename5“ (macht Ubuntu beim Systemstart), deshalb habe ich sie zuerst umbenannt. Vorher müssen sie aber heruntergefahren werden:
sudo ip link set rename5 down
sudo ip link set rename5 name zehnGb1
sudo ip link set zehnGb1 up
Kommt man zu der momentan aktiven Schnittstelle unterbricht man natürlich die SSH-Sitzung und muss am Server direkt den Namen ändern und die Schnittstelle wieder hochfahren.
ACHTUNG:
Wie ich festgestellt habe hält dieses Umbenennen nur bis zum nächsten Neustart. Will man es permanent haben, so muss man händisch eine udev-Regel erstellen. Hier gibt es zudem Neuerungen seit Ubuntu 15.10. Es scheint, dass die Datei „/etc/udev/rules.d/70-persitent-net.rules“ nicht mehr automatisch erzeugt wird. Deshalb halten wir die Sache simpel und leben mit „rename4“ und „rename5“. Näheres zu „udev“ und den Regeln gibt es bei ask-ubuntu-networking und bei wiki-ubuntu-users.
Einzelne LAN-Adapter (das Mainboard hat 2 x 10 Gb/s) bündeln
Ändern der Schnittstelleneinstellungen in der /etc/network/interfaces-Datei
mit dem Zusammenlegen zweier Schnittstellen für maximalen Datendurchsatz (bonding/Bündelung).
Eine Anleitung gibt es auch bei help.ubuntu.com, bei wiki.ubuntuusers.de oder im „Praxishandbuch Ubuntu Server 14.04 LTS“ von C. Kühnast und D. van Soest. Diesmal ist die Beschreibung im Praxishanbuch Server sogar richtig ausführlich.
Um „rename4“ und „rename5“ zu kombinieren benutzen wir das „IEEE 802.3ad-LACP-NIC-bonding-Protokoll“ (NIC-bonding = network-interface-card-Bündelung). Es ist das am einfachsten zu etablierende und das einzige, das der Mac versteht. Außerdem entscheidet es selbstständig, wie es den höchsten Datendurchsatz bekommt und fällt beim Ausfall einer Schnittstelle automatisch auf die andere Schnittstelle zurück.
sudo vim /etc/network/interfaces
#rename4 ist manuell und ein "Slave" zu "bond0"
auto rename4
iface rename4 inet manual
bond-master bond0
#rename5 ist daseblbe damit ein 2-Link-Bond.
auto rename5
iface rename5 inet manual
bond-master bond0
# bond0 ist eine „gebondete“ Schnittstelle und kann
#wie jede andere Schnittstelle benutzt werden
# bond0 hat eine statische IP-Adresse
auto bond0
iface bond0 inet static
address xxx.xxx.xxx.10
gateway xxx.xxx.xxx.1
netmask 255.255.255.0
# bond0 benutzt das IEEE 802.3ad LACP
#bonding protocol (wie der Mac z. B. auch)
bond-mode 4
bond-miimon 100
bond-lacp-rate 1
bond-slaves rename4 rename5
Alles speichern und Service neu starten:
sudo service networking restart
Man kann dann schauen, wir der Zustand der Schnittstellen ist mit:
sudo ip address show
oder den Zustand des Bondings ausführlich darstellen:
sudo cat /proc/net/bonding/bond0
Wie der Bond die Pakete verteilt
Es gibt dafür verschiedene Möglichkeiten. Es werden entweder die MAC-Adressen benuzt oder zusätzlich die IP-Adressen. Die Bonding-Dokumentation gibt es bei www.kernel.org und sie hat dazu einige Angaben.
Die Voreinstellung „layer2“ verteilt den ganzen Verkehr auf einen Slave. Es gibt für Linux dann noch „layer3+4“ die für die Berechnung der Pakete auch Layer 3 Informationen (IP-Adressen) benutzt. Wenn ich das richtig verstehe leitet „layer2“ immer alles über eine Leitung (Slave), weshalb man über folgende Einstellung „layer3+4“ setzten sollte:
bond-xmit_hash_policy layer3+4Beim Switch (siehe weiter unten) kann man ebenfalls verschiedene Methoden einstellen. Was hier aber wirklich den besten Durchsatz bringt habe ich noch nicht getestet. Hier der Auszug aus der bond0 Abfrage am Server:
sudo cat /proc/net/bonding/bond0
Ethernet Channel Bonding Driver: vX.X.X
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer3+4 (1)
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms): 0
Beim Switch habe ich momentan „Source/Destination MAC, Ethertype, Incoming Port“, was nur eine 1:10 Verteilung für die zwei LAN-Leitungen ergibt, also im Grunde geht alles über eine Leitung. Ein Umstellen auf „Source/Destination IP and TCP/UDP Port Fields“ hat aber auch nichts gebracht.
Test:
Bei meinem 10 GB Testordner gab es leider keine Unterschiede, es blieb bei den 2’40“ auch wenn ich am Switch zusätzlich von MAC-In/Out auf IP-In/Out umgestellt habe gingen doch alle Daten über eine einzelne Leitung. Nur die Netzwerkarktivitätsanzeige zeigte plötzlich werte wie 270 MB, die nicht stimmen können, da das theoretische Maximum bei 250 MB liegt und zudem die Zeiten dieselben sind und beim Paketmonitor des Switches man eindeutig sieht, dass alle Daten über eine einzlene Leitung gesendet werden.
Jetzt sollten wir aber zuerst den Switch einrichten.
Einen HP-Switch für Bonding einrichten
IP-Adressen im Switch einrichten
Ich habe einen Switch von der Firma HP genommen mit 24 Anschlüssen. Er muss managed/verwaltet sein. Ein Switch hat eine eigene Intelligenz und kann zwei Geräte im Heimnetz direkt (Layer 2) miteinander verbinden, ohne dass das Signal über den Router (Speedport/fritz.box etc.) gehen muss. Am Anfang verbindet man den Switch am Besten erst gar nicht mit dem Router, da man ihm zuerst die Adresse des Routers mitteilen muss. Und dafür muss man an die Einstellungsebene.
Um an die Einstellungsebene des Switches zu gelangen nur den Switch mit einem Rechner verbinden. Dann auf dem Rechner das Adressfeld des Switches einstellen. Beim Mac geht das ganz einfach:
Systemeinstellungen-Netzwerk (IP-Adresse nach HP-Swich-Bedienungsanleitung)
- Oben eine neue „Umgebung“ wählen oder eine alte „Umgebung“ bearbeiten.
- IP-Adresse: 192.168.1.12
- Teilnetzmaske: 255.255.255.0
- Router: 192.168.1.1
Dann „Anwenden“ drücken. Wenn die alte Mac-Netzwerkumgebung nicht überschrieben ist, können wir sie mit einem Klick später wieder herstellen. Wir brauchen diese Einstellung am Mac nur um einmal in den Switch zu kommen.
Jetzt in den Switch unter der HP-Vorgaben-IP-Adresse: 192.168.1.12, mit einem Browser einloggen. User ist „admin“, Passwort ist leer.
Dann hier die IP-Adresse des eigenen Routers eingeben und die IP-Adresse unter der sich der Switch am Router immer anmelden soll. Alles speichern und den Switch neu starten. Jetzt am Rechner, mit dem wir uns eingeloggt haben (bei mir war es, wie oben beschrieben, ein Mac), wieder den alten Zustand herstellen. Einfach wieder die alte Umgebung auswählen. Jetzt ist der Switch auf den eigenen Router eingestellt und man erreicht ihn unter seiner neuen IP-Adresse.
Bonding am Switch für den Server einrichten
Auf den Menüpunkt „Trunks“ gehen, dann auf „Configuration“ dann „TRK1“ markieren und auf „Edit“.
Auf einem HP-Switch bonding einrichten. „Static Mode“ auf „Disabled“!
„Static Mode“ muss man unbedingt auf „Disabled“ stellen, sonst ist es kein IEEE 802.3ad-LACP und passt nicht zu dem was wir auf dem Server eingerichtet haben und der Mac versteht es dann auch nicht. Dann noch aus der Port List die zwei Ports auswählen, in die später die zwei LAN-Kabel des Servers kommen und fertig.
Man sollte dann am Switch noch die Zeit einstellen, das Passwort ändern etc.
Und später noch das Bonding für den Mac einrichten. Das ist dann TRK2, mit den gleichen Werten wie für die Serveranschlüsse, bis auf die Ports in die die zwei LAN-Kabel es Mac kommen.
Bonding am MAC einrichten
Das Bonding am Server haben wir ja schon eingerichtet, das macht aber alles nur Sinn, wenn es auf der anderen Seite auch einen Rechner gibt, der ebenfalls auf zwei LAN-Leitungen gleichzeitig feuern und empfangen kann.
Am Mac versteckt sich das „Bonding“ oder „Truncking“ wieder im Dialog:
Systemeinstellungen-Netzwerk
Dann oben „Ethernet“ auswählen und nun links unten am kleine Rädchen das Menü aufklappen und „Virtuelle Anschlüsse verwalten …“ wählen. Hier die beiden Ethernet-Anschlüsse auswählen und mit „Anwenden“ die Einstellung abschließen.
Jetzt zurück zum Switch und dort das Bonding für den Mac – wie oben beschrieben – einrichten!
Fertig.
Letzte Kontrolle am Server
Hat man den Server neu gestartet und mit „ip address show“ sind die LAN-Ports immer noch auf „down“ so kann man sie nochmals nach „up“ schieben und den Netzwerkprozess nochmals neu starten.
sudo ip link set zehnGb0 up
sudo ip link set zehnGb1 up
sudo service networking restart
Jetzt sollte man ein Funktionierendes Bond haben.
sudo cat /pro/net/bonding/bond0
DNS Probleme Router und statische IP-Adresse
Nach der Vergabe einer statischen IP-Adresse können die Router, da sie nicht mehr DHCP anwenden meist den Namen des Servers nicht mehr automatisch in eine IP-Adresse umwandeln (localhost DNS) Abhilfe schafft beim MAC eine Änderung in der /etc/hosts-Datei. Im Terminal, direkt am Mac, im normalen Fenster ohne SSH-Einwahl:
sudo vim /etc/hosts
Dann unten erst die IP-Adresse des Servers eintragen und dahinter seinen Namen. Jetzt klappt das Einloggen in SSH wieder mit „user@servernamen„. Es kommt aber am Anfang eine Meldung, dass SSH diesen Servernamen mit der IP-Adresse so nicht kennt. SSH lässt aber ein Login trotzdem zu.
Wie schnell ist das Netzwerk, mit zwei gebündelten Mulitplex 1 Gb/s-LAN-Schnittstellen?
Mein Testordner hatte 10 GB und ca. 2.500 Dateien.
Wie schnell ist der Server und das RAID?
Vom Verzeichnis „/home“, das auf der Samsung-SSD liegt zum RAID 6 mit dem Adaptec Controller und zurück waren es folgende Werte:
SSD zu RAID 6 – 14,5 Sekunden = 690 MB/s Schreibgeschwindigkeit für das RAID
RAID 6 zur SSD – 13 Sekunden = 769 MB/s Lesegeschwindigkeit für das RAID
Wie schnell ist das Netzwerk?
Vom MacPro wurde derselbe Ordner einmal über das Netzwerk auf das RAID 6 geschrieben und einmal anders herum:
MacPro –> Netzwerk –> RAID 6 – 2 Minuten 41 Sekunden
RAID 6 –> Netzwerk –> MacPro – 2 Minuten 44 Sekunden
In Bytes und Bits
Eine Gigabit-LAN-Leitung sollte 1 Gigabit pro Sekunde machen. Da wir uns bei Leitungen auf der Hardwareseite befinden, und diese in Herz getacktet ist, ist damit ein Wert zur Basis 10 gemeint, also: 109 = 1.000.000.000 bit.
Auf der Software Datenseite rechnet man aber im dualen System also zur Basis 2, dies meint: 1 Gigabit = 230 = 1.073.741.824 bit.
Der Leitungsdurchsatz ist damit 109/230 = 0,93132 Gibit/s – zur Basis 2.
Die kleinste adressierbare Adresse hat in der Computrtechnik 8 bit, weshalb man auf Softwareseite wiederum mit Bytes statt mit bits rechnet.
1 Gigabyte sind 8 Gigabit
Damit ist der theoretische Leitngsdruchsatz: 0,93132 Gibit/s geteilt durch 8 = 0,116415 GiByte/s oder 116,415 MiByte/s (das zusätzliche „i“ steht für zur Basis 2).
Unser Testdatei hatte 10 GiByte (zur Basis 2).
2’40“ sind 160 Sekunden. Also 10 GiByte geteilt durch 160 Sekunden = 0,0625 GiByte/s oder 62,5 MiByte.
Eine einfache LAN-Leitung macht theoretisch 116,415 MiByte/s, da sie gedoppelt ist müsste sie also theoretisch 232,83 MiByte/s machen.
Den tatsächlichen Durchsatz 62,5 MiByte/s geteilt durch den theoretischen von 232,83 MiByte/s macht 26,84%, das ist nicht greade üppig.
Es ist aber schwer nachvollziehbar, wo das Ganze, jenseits von normalen Protokollverlsuten und Overhead, hängt oder einen Engpass hat.
Es könnte der Mac-Client sein, der Switch oder die Serverkonfiguration. Hier gibt es noch Testbedarf. Ich freue mich auch über Anregungen und Tipps!
*Anmerkung 2020
Die gekoppelte LAN-Leitung überträgt nur auf einer Leitung, die zweite Leitung wird nur für gleichzeitige Aktivitäten genutzt! Die Verdoppelung ist eine falsche Annahme.
Die theoretische Geschwindigkeit, wird laut Protokoll des Linuxprogramms „iftop“ fast erreicht mit 115MB/s Spitze und 107MB/s Durchschnitt beim Empfangen habe ich wohl das Limit ziemlich ausgereizt.
X. Verschicken von Statusmeldungen per Mail
Einrichten eines Mail-Servers, so dass man Statusnachrichten durch Ubuntu verschicken kann
Die Ventilatoren pumpen, der 10 GB-LAN-Controller wird zu heiß, fail2ban hat jemandem ausgeschlossen, es gibt viele Stellen, an denen einzelne Servermodule Nachrichten verschicken können. Doch ohne Mail-Server gibt es keinen Punkt an dem die Nachrichten abgeschickt werden können.
Mit dem Programm „postfix“ kann man einen Minimal-Mailserver einrichten, der genau das macht, nämlich Statusmeldungen an eine vorgegebene Emailadresse verschicken.
sudo apt-get update
apt-get -fym install postfix
Email-Server Postfix nur für Systemnachrichten
Man wählt „Nur lokal“, damit wird ein minimales System installiert, das aber alle Mails nur lokal vorhält und auch nur lokale Mails akzeptiert. Diese könnten mit dem Programm „Mutt“ auch gelesen werden, was aber natürlich zu umständlich ist. Deshalb gibt es noch Zusätze.
Als Domainabsender kann eine beliebige Doamain-Adresse gewält werden, z. B. mein.datengrab.de
Einen Domainnamen zuteilen.
Mails an Root nach außen weiterleiten
Um die Mails an Root nach außen zu leiten, muss die Konfiguration geändert werden, da es momentan auf „local“ begrenzt ist.
In der Datei „/etc/aliases“ trägt man die Zielmailadresse ein und für den Postmaster, der auch bestehen muss, ebenfalls:
sudo vim /etc/aliases
postmaster: meineNormaleEmail@meinNormalerAccount.de
root: meineNormaleEmail@meinNormalerAccount.de
ESC
:wq
Dem Mailprogramm mitteilen, dass es Änderungen gibt und diese auch übernommen werden!
sudo newaliases
Nun muss die Datei „/etc/postfix.main.cf“ angepasst werden:
Beim relayhost (Zielhost) müssen die eckigen Klammern bleiben! Bei meinem Provider muss vor den Domainnamen noch der Zusatz „mail.“ (mail.DOMAIN.de), dann musste ich die 587 angeben für eine verschlüsselte Verbindung und die nächste Zeile mit „smtp_tls_security_level = may“
sudo vim /etc/postfix.main.cf
…
myhostname = meinServer
mydestination = meinServer, localhost.localdomain, localhost
…
relayhost = [mail.meinNormalerEmailAccount.de]:587
smtp_tls_security_level = may
smtp_sasl_auth_enable = yes
smtp_sasl_password_maps = hash:/etc/postfix/sasl/sasl-passwd
smtp_always_send_ehlo = yes
smtp_sasl_security_options = noanonymous
#default_transport = error
#relay_transport = error
Um die Verbindung zu meinem Provider zu ermöglichen muss noch „SMPT-Submission“ eingerichtet werden, das den Versand über Port 587 ermöglicht.
Auskommentieren aufheben/Rauten # entfernen
in:
/etc/postfix/master.cf
sudo vim /etc/postfix/master.cf
submission inet n - - - - smtpd
-o smtpd_tls_security_level=encrypt
-o smtpd_sasl_auth_enable=yes
-o smtpd_relay_restriction=permit_sasl_authenticated,reject
Speichern und Service neu starten. Siehe unten.
Dann habe ich noch die libsasl2-modules installiert. Ob das nötig ist weiß ich nicht, es gab aber einen Hinweis im Netz.
sudo apt-get install libsasl2-modules-sql
Als nächstes müssen die Zugangsdaten über für den Server, über den die Emails versendet werden sollen eingegeben werden. Dafür müssen wir im Ordner „sasl“ eine „sasl-passwd“-Datei anlegen. Bei meinem Provider muss wieder „mail.“ vor den Domainnamen. (Der Ordner „sasl“ scheint neu zu sein früher lag die Datei „sasl-passwd“ direkt in „/etc/postifix“.)
/etc/postfix/sasl
sudo touch sasl-passwd
sudo vim sasl-passwd
mail.meinNormalerEmailAccount.de loginname:passwort
#ESC-Taste drücken
:wq
Aktualisieren der Datenbank mit den neuen Angaben. Es wird mit „postmap“ eine „.db“ Datei kreiert, die man genauso wie die ursprüngliche Datei gegen fremden Zugriff schützen sollte, da sie beide das Mailpasswort unverschlüsselt enthalten.
sudo postmap /etc/postfix/sasl/sasl-passwd
sudo chmod 0600 /etc/postfix/saslasl-passwd /etc/postfix/saslsasl-passwd.db
Momentan wird über einen externen Server eine Email mit dem Absender root@meinDatengrab.de versendet. Damit stimmen Absender-Account und Absenderadresse nicht überein und werden von den meisten Spamfiltern nicht durchgelassen. Deshalb muss jetzt noch die Absenderadresse mit der Adresse des eigentlichen Versandservers angeglichen werden.
sudo vim /etc/postfix/main.cf
…
canonical_maps = hash:/etc/postfix/canonical
…
Dann in der Canonical Datei:
sudo vim /etc/postfix/canonical
root myEmail@myForeingServer.de
Aktualisieren („postmap“) der Datenbank mit den neuen Angaben:
sudo postmap /etc/postfix/canonical
„postmap“ kreiert jedes Mal eine neue Datei mit der Endung „.db“ im selben Ordner.
Postfix neu starten:
sudo service postfix restart
oder
sudo /etc/init.d/postfix reload
Ich beziehe mich hier wieder auf den „Kofler“, aber es gibt auch direkt bei Postfix gute Angaben zur Konfiguration.
Mailversand testen
Am Eingabeprompt von SSH muss man zu „telnet“ wechseln:
telnet localhost 25
Trying ::1...
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
220 mail ESMTP Postfix
helo localhost
250 mail
mail from:testing@example.com
250 Ok
rcpt to:root
250 Ok
data
354 End data with <CR><LF>.<CR><LF>
Suject: Test von Thomas
Der Mailtext, der versendet werden soll.
.
250 Ok: queued as B58E141D33
quit
Achtung der Punkt am Ende muss alleine in einer Zeile stehen und gehört dazu! Er bedeutet Data-Ende.
Falls es Problem gibt kann man Postfix neu konfigurieren.
Aber Achtung es werden zuvor auskommentierte Angaben in „main.cf“ unten wieder neu eingefügt.
dpkg-reconfigure postfix
IPMI-Statuswarnungen aktivieren und über einen externen Mail-Server direkt verschicken
Im Gegensatz zu Linux braucht IPMI keinen zusätzlichen Mailserver. Wählt man sich über den IPMI-LAN-Kanal am Mainboard ein, so kann man dort Email-Server-Daten hinterlegen, damit bei Problemen eine Statusmail verschickt werden kann. Im Gegensatz zum Einrichten mit Postfix (für die Satusmails die vom Linux-System kommen), gibt es bei IPMI eine Testmailfunktion, was die Sache wesentlich einfacher macht.
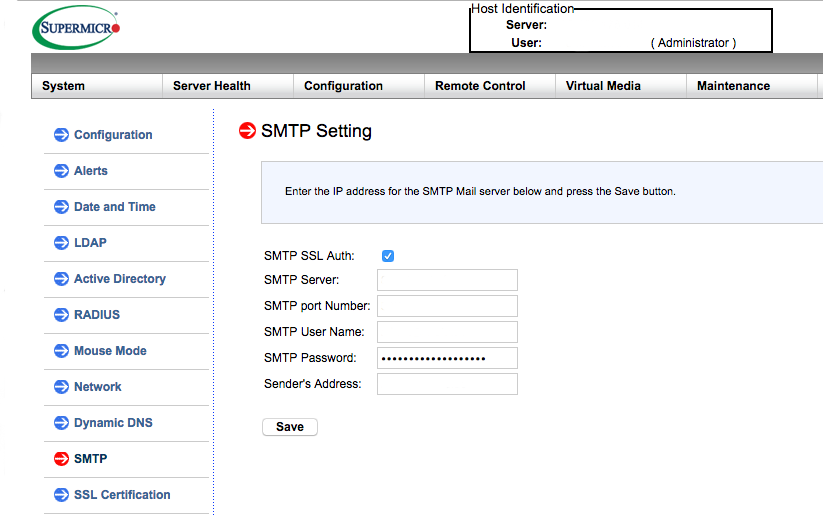
Status Mails von IPMI verschicken – Achtung mit den Sonderzeichen im Passwort hier gibt es Beschränkungen!
Die Mails werden über einen externen Provider verschickt – in der Regel Ihr normaler Email-Account. Die Daten sind die gleichen, wie sie auch in Email-Programmen eingegeben werden müssen.
Achtung:
Bei mir ging es nicht, ohne dass ein klar ersichtlicher Grund vorlag. Mein Provider ist dann für mich die Logdateien durchgegangen und konnte erkennen, dass das Passwort immer abgelehnt wurde. (Es war Gott sei Dank nicht die Telekom oder sonst ein Verein mit grauenhafter Telefonhotline, sondern snafu in Berlin.) Das Passwort stimmte, nur hatte es ein paar Sonderzeichen z. B. ein „=“. Das führte wohl dazu, dass IPMI das Passwort geändert oder einzelne Zeichen ignoriert hat. Nachdem ich das Passwort vom Gleichheitszeichen befreit hatte, ging es plötzlich. Vielleicht lag es auch an der Passwortlänge, die bei IPMI auf 20 Bit beschränkt ist (siehe weiter oben unter IPMI).
Das sind Fehler, bei denen man endlos suchen kann! Danke an snafu und der Hotline, bei der ein Fachmann am Telefon sitzt und auch sofort den Hörer abnimmt – ohne Telefonvertröstungsanlage – boh ey!
Nachdem der Mailzugang bei einem externen Provider eingerichtet ist, kann man unter „Configuration – Alerts“ die gewünschten Benachrichtigungen einrichten.
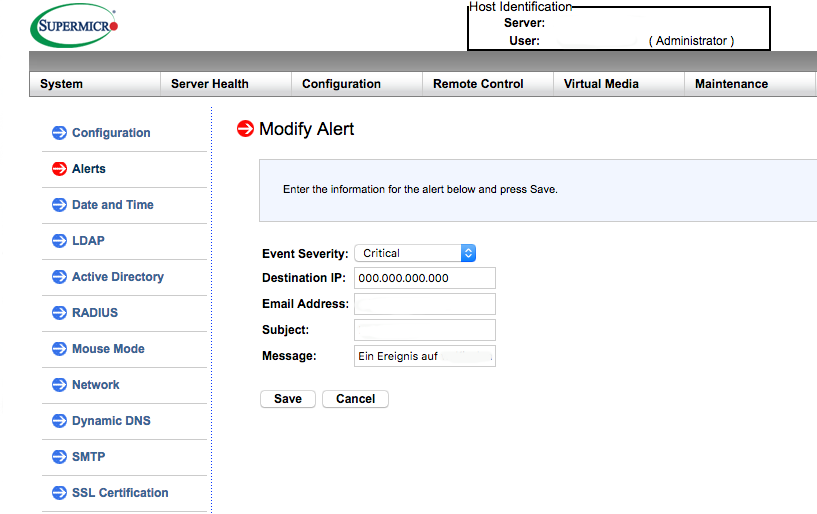
IPMI Benachrichtigungen einrichten. Die Destination-IP-Adressen-Nullen können ignoriert werden.
Hier kann man den Event einrichten und dann die Email-Adresse angeben. Klickt man im Menü zusätzlich auf „Help“, dann erscheinen rechtes Erklärungen. Die Destination-IP kann auf Null gelassen werden. Das Ganze speichern und dann per Knopfdruck: „Send Test Alert“, Testmail verschicken.
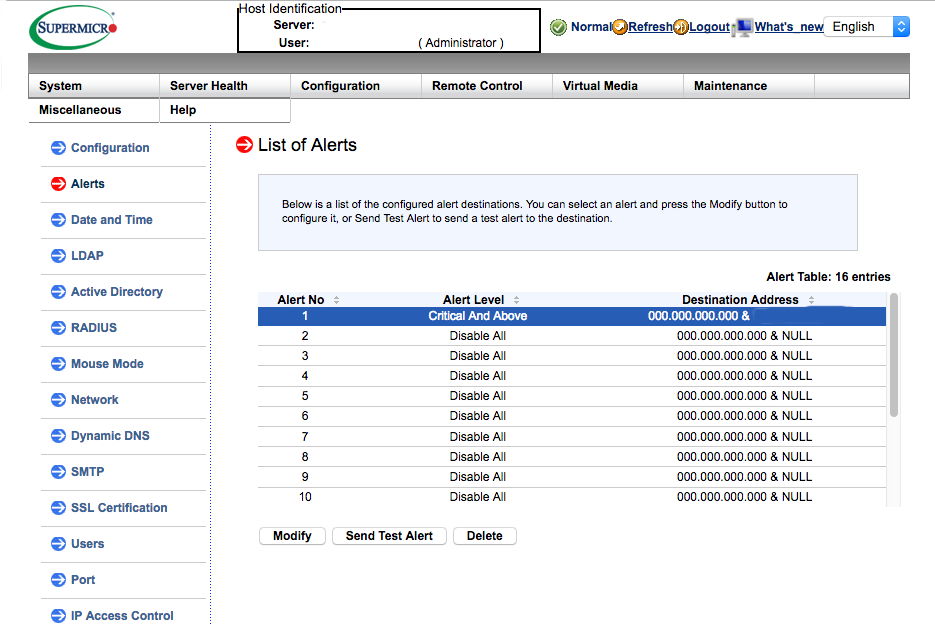
Test Mail um zu prüfen, ob alles funktioniert.
ACHTUNG
Da bei mir die Lüftersteuerung immer noch nicht verlässlich funktioniert und gerade im Winter auch mal unter den Schwellwert von 300 U/min geht, führt dies manchmal dazu, dass das System dann alle 5 Sekunden für die nächsten Tage Mails verschickt. Das kommen dann schnell ein paar Tausend Mails zusammen. Das kann, wenn man auf Reisen ist, sehr ärgerlich sein, da das Mail-Konto dann praktisch nicht mehr zugänglich ist. Deshalb habe ich die Funktion ausgeschaltet. Siehe dazu auch die Rubrik –> Ungelöste Probleme
Email-Nachrichten über den Zustand des RAIDs verschicken
maxView-Storage-Manager verwaltet und erstellt nicht nur RAIDs sondern das Programm kann auch Statusmeldungen per Email verschicken. Man muss links die Ebene unterhalb von „Enterprise View“ auswählen, das ist der Name des Servers, und dann unter „System“ – „System Settings“ die Einstellungen vornehmen.
Hier ist der zweite Reiter: „SMPT“, in den die Daten für den Zugang zu einem externen Mailserver kommen.
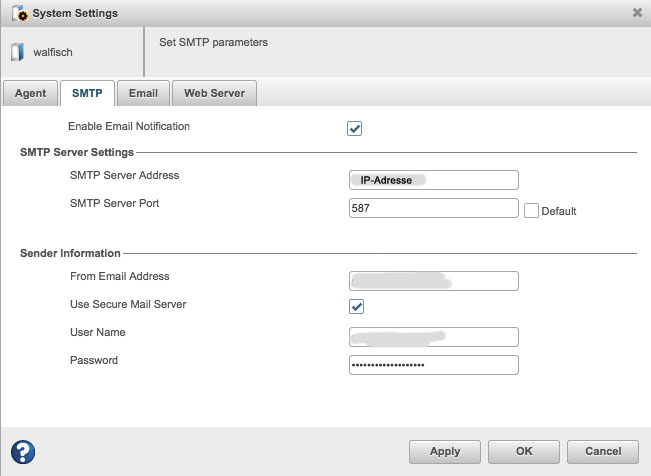
maxView Statusmails verschicken – einrichten von SMPT – Achtung es muss mit der IP-Adresse gearbeitet werden, nicht mit dem Namen!
Für den Server muss eine IP-Adresse ausgewählt werden, da es hier nicht unbedingt einen Zugang zu einem DNS-Server gibt. (Bei mir hat es nur mit der IP-Adresse funktioniert.)
Für „From Email“ am besten die eigene Mail eintragen, die auch auf dem Mailserver angemeldet ist, damit es nicht zu Spam-Verwechslungen kommt.
In einem zweiten Fenster kann man dann die Art der Statusmeldungen und die dazugehörigen Email-Adressen anlegen:

Einer Email-Adresse die jeweiligen Meldungen zustellen.
Von hier aus kann man wiederum Testmails verschicken.
Den Reiter Agent, der sich auf interne Meldungen bezieht, die man auch an Ubuntu schicken kann und den Reiter „Web Server“, der einen Port angibt, habe ich in den Voreinstellungen gelassen.
Anhand der zugestellten Testmail sieht es bei mir so aus, als ob das Programm Postfix für den Versand zum externen Server benutzen würde, da die angegebene „Event Source“ die Postfix-Serveradresse ist.
TIPP:
Unter „Agent“ kann man auch den Tonalarm einstellen und nach dem Auslösen wieder abstellen!
XI. ungelöste Probleme
- Die Lüfter pumpen nach wie vor manchmal nach einem Neustart des Servers. Manchmal funktionieren sie aber auch normal. Supermicro hat dazu keinen Rat, außer dass man kleine laute Lüfter nehmen soll, die mit über 700 U/Min. drehen und dass nach 30 Sekunden ohne Strom IPMI zurückgesetzt wird. Für das Mainboard, mit der riesigen Heatpipe, könnte ich auf die Lüfter ganz verzichten, aber der Raid-Controller und vor allem der Controller für das 10 GB-LAN entwickeln doch ein wenig Wärme (siehe den Hardware Teil).
- Bei smb funktioniert die Browsing Funktion nicht. Wer ist hier der WINS-Server? Man muss sich am Mac immer mit „Mit Server verbinden …“ einwählen. Normalerweise müsste das System selbstständig die vorhandenen Freigaben erkennen. Seit ich von DHCP auf feste IP-Adressen umgestellt habe geht dies nicht mehr. Alle Hinweise aus dem Netz habe bisher keinen Erfolg gebracht.
- Mein Router erkennt seit ich feste IP-Adressen habe auch den Servernamen nicht mehr. Hier half ein händischer Eintrag in „/hosts“ am Client-Mac. Wie man am Router die DNS-Einträge verwaltet habe ich nicht herausbekommen.
- sFTP und „chroot“ geht nur wenn das „chroot-Verzeichnis“ innerhalb von „/home“ liegt. Wenn es außerhalb von „/home“ liegt geht es mit dem Linux-SSH-Server nicht. Als Ersatz, habe ich jetzt für unsere Hauptfiliale im Schwarzwald einen VPN-Kanal eingerichtet und ganz auf FTP verzichtet.
XII. Abschließende Betrachtungen
Misst man das Ergebnis an den Vorgaben, so war das Projekt erfolgreich.
Die Lärmentwicklung ist so minimal, dass sie weit unter dem Rauschen der leisen Bleibtreustraße in Berlin liegt und auch unter dem Rauschen der Heizung im Winter, ganz zu schweigen von normalen NAS-Servern, die man sich neben den Schreibtisch stellen kann. Der Lüfter im Netzteil dreht extrem langsam und die beiden anderen Lüfter liegen momentan bei 300-400 U/Min. Der Stromverbrauch des gesamten Systems reicht zwischen 35 Watt im Ruhezustand und 110 bis 120 Watt bei Volllast. Beim Überspielen von 10 TB auf den Server lag der Stromverbrauch jedoch lediglich bei 45 bis 55 Watt. Die Geschwindigkeit des Serves und des RAIDs sind perfekt, mit ca. 14 Sekunden für 10 GB und 2.500 Dateien (lesen 769 MB/s und schreiben 690 MB/s). Die Geschwindigkeit über das gebündelte LAN mit 2 Minuten 40 Sekunden für 10 GB ist ebenfalls akzeptabel. Der längliche Quader hängt als schönes Objekt in unserem 4K-Video-Postproduktionsbüro und ist ordentlich schwer, dazu noch fest mit der Wand verbunden, so dass er nicht so einfach von potentiellen Einbrechern mitgenommen werden kann. Der Kamineffekt, mit der aufsteigenden warmen Luft innerhalb des Quaders, funktioniert perfekt.
Was die Software betrifft, so ist dies natürlich ein Objekt stetiger Optimierungen und Aktualisierungen. Dadurch, dass die beiden Systeme, Betriebssystem und Raid-Controller mit den Daten, komplett getrennt sind, sehe ich hier eine gewisse Beständigkeit für den Datenteil, der von Eingriffen in Ubuntu nicht tangiert wird. Den Gesamtpreis habe ich noch nicht ausgerechnet, aber er liegt für 39 TB effektiven Speicherplatz (RAID 6 – zwei Festplatten können ausfallen) und den oben angegebenen Geschwindigkeiten, unter 5.000 Euro.
In manchen Anleitungen wird am Anfang ein Zeitumfang angegeben. Für mich kann ich sagen, für das stückweise Entwickeln, sowohl auf Hardware- als auch auf Softwareseite, sind einige Monate ins Land gegangen. Meine Freundin fand es sehr amüsant, dass ich an manchen Tagen jeweils zweimal zum Baumarkt und zweimal zu Conrad-Electronic gefahren bin. Ein Prototyp hat so seine Tücken, gerade dann wenn man nicht nur Bauteile zusammensteckt, sondern ein eigenes Konzept hat, für das man das eine oder andere Bauteil anpassen oder auch herstellen muss.
Serverbau, als die Gestaltung schöner Objekte, die keinen Lärm erzeugen und mit wenig Strom auskommen, hat meiner Ansicht nach in Zeiten von Home- oder Büro-Clouds eine Zukunft. Nicht jeder möchte seine Daten zum Auswerten nach Amerika schicken und dann über Windows 10 jeglichen Zugriff protokollieren und verwerten lassen.
Insgesamt habe ich eine Menge gelernt, vor allem über Linux und das Funktionieren von Computern an sich. Über Anregungen und Optimierungsvorschläge würde ich mich freuen!
Vielen Dank für die extrem ausführlich und sehr gut beschriebene Anleitung.
Habe ein paar Dinge von Ihnen umgesetzt. Betreibe seit ca. Mitte Juni 2016 einen kleinen Samba Server zu Hause auf Basis von Ubuntu Server 16.04.
Es ist schon witzig, welche Energie, welchen Aufwand und auch welchen Einfallsreichtum manche Leute in Ihre Projekte stecken. Das Ganze erinnert mich an „Hör mal wer da hämmert“. Trotzdem, ein schöner Dinosaurier ist es geworden 😉
An einem Tag kann man sowas realisieren, wenn man einen Mac mini mit 8GB und SSD und ein Promise Thunderbolt Raid mit jeweils passender Bestückung kauft und zusammen mit macOS-Server durchkonfiguriert.
Fertig!
Ich habe das schon 100x bei Kunden gemacht, danach hat man bis auf gelegentliche Updates oder ausfallende Platten (was ja bei einem RAID 5 oder 6 kein Problem ist), jahrelang Ruhe.
So eine Konfiguration hält 2 Plattenleben lang, also 7-8 Jahre.
Danach sieht die Welt sowieso wieder ganz anders aus.
Der DNS und evtl, auch der DHCP-Server sollte dann ebenfalls im macOS Server laufen und im 0815-Router deaktiviert werden.
116MB/s bei einer Gigabit-Leitung wird bei großen Dateien sowohl mit AFP als auch mit SMB (Verschlüsselung bei SMB deaktivieren!) problemlos erreicht, 2x 1GB bündeln geht mit einem zusätzlichen Thunderbolt auf Gigabit-Ethernet Adapter für 30€, das geht auch noch mit 2 Adaptern (einen an Thunderbolt Port 2 am Mini, einen am Promise RAID Port 2 für eine 3fach-Bündelung (entsprechendes Bonding am Switch vorausgesetzt).
10Gb-Interfaces sind am Mini nur via Thunderbolt möglich (teuer) und machen nur Sinn, wenn die Clients das auch haben (iMac Pro) und ein entsprechend teuerer Switch angeschafft wird. Meiner Meinung nach ist das derzeit noch nicht sinnvoll.
Hochleistungsworkstations kann man wesentlich günstiger via Ethernet over Thunderbolt direkt am Server anschließen.
Ach ja, weil´s bisher nicht erwähnt wurde, an ein Backup sollte man natürlich auch noch denken, was bei 48TB brutto vor RAID auch nur mit einem weiteren RAID oder NAS geht. Aber zum Glück gibt es ja inzwischen zahlbare 10- und 12TB-Festplatten.
Danke für den ausführlichen Kommentar! Man muss allerdings folgendes bedenken: Für ein Promise Thunderboldt Raid muss man ca. 5.000 bis 6.000 Euro in der Größe rechnen, plus den Mac-Mini. Und was man nicht vergessen darf, der Lärm den diese Kombination dann macht. Ich habe auch noch ein Thunderbolt-G-Raid im Einsatz, das mich 6.500 Euro gekostet hat. Der Lärm, den das Ding veranstaltet, ist unglaublich. Außerdem wird das Ganze auch schön warm (öfters mal eine Warnung vor Überhitzung) wenn man Filme schneidet, also stark darauf zugreift. Ja, meine Lösung ist groß, ja, es macht Arbeit, ja, es kostet auch Geld aber man hat damit auch etwas Eigenes an der Wand hängen und nicht schon wieder so eine Apple-Kiste. Und was so ein macOS-Server dann mit den Daten macht, kann auch keiner garantieren, da ist Linux einfach die bessere Lösung. Wir müssen ja nicht alle Daten freiwillig zu Apple-NSA schicken. Im Grunde ist meine Konstruktion eine Plastikplatte, auf die man ein paar Festplatten und ein Motherboard schraubt. Also, wer das mit der Schönheit, Lärmdämmung und der Diebstahlsicherheit nicht braucht, kann auch ein paar Festplatten auf eine Spanholzplatte schrauben und das ganze im Keller zusammenstecken. Das ist dann auch an einem kühlen Winterabend mal schnell gemacht. Die Festplatte an sich ist sowieso ein Dinosaurier, wenn man so ein Ding mal aufmacht, hat man das Gefühl, man hat gerade ein Röhrenradio geöffnet. Es ist ein Relikt aus der Zeit der Mechanik, wie das Tonband, die Schallplatte, die elektrische Schreibmaschine und auch das Röhrenradio. Feinste Mechanik inmitten eines modernen Computers, kaum zu glauben, dass es sowas noch gibt. Wir alle warten auf die bezahlbare SSD-Lösung oder den Speicherchip im Peta-Bereich.
Klasse Beitrag! Schön zu sehen dass auch andere Kollegen ähnliche Wege gehen. Als Designer, Innenarchitekt mit reichlich viel IT Erfahrung, (Dozent an einer Hochschlue für Gestaltung) entwickle ich seit ca 20 Jahren meine Serversysteme selbst. Manch Einer fragt sich warum. Nur so kann ich meine speziellen Ansprüche realisieren ohne die Sicherheitsaspekte zu vernachlässigen. Insbesondere im Hinblick auf die neue jetzt im Mai in Kraft tretende DSGVO.
Ich habe mittlerweile mehrere Server unter Ubuntu laufen. Einen Fileserver, einen Entwicklungsserver und einen Pull-Backupserver (mit Rdiff-Backup) der täglich automatische Backups erstellt.
Danke für die Rückmeldung. Der Backupserver ist ebenfalls eines meiner nächsten Projekte. Allerdings habe ich mittlerweile ein Mengenproblem, da ich durch die Filmdaten nur noch in TB rechnen kann. 100 TB sind da immer schnell voll. Die Alternative scheinen LOT-Bänder zu sein.
Von Bändern halte ich nicht mehr wirklich viel. Habe früher viele Kunden aus dem Architektursektor gehabt, die (für damalige Verhältnisse) sehr große Datenmengen zu sichern hatten. Die Haltbarkeit und Robustheit der Bänder gegen äußere Schadeinflüsse ist nicht sonderlich gut. Z.B. Magnetfelder, Wärme, Feuchtigkeit & Schimmel. Der einzige Vorteil ist der Preis / TB.
Ein Backupserver der Inkrementelle Backups macht ist für reine Datensicherung schon eine gute Lösung. In Ihrem Fall hieße das die bisherige Kapazität mindestens x2 als Speicherplatz vorhalten. Das ist dann schon eine Hausnummer. Andererseits, kann und sollte man nicht mehr benötigte Projekte archivieren, dann hält sich der Verbrauch ja auch in Grenzen.
Ich würde in so einem Fall auf günstigere langsamere Festplatten setzen. Die sind einerseits günstiger und andererseits auch langlebiger, da sie sich nicht so schnell erwärmen. Trotzdem gibt es halt bei Festplatten immer auch die magische 5 Jahres Grenze, nach der die Fehleranfälligkeit steigt.
Wir alle warten sehnlichst auf den holografischen Speicher mit mehreren Petabyte im 2cm großen Kristallwürfel. 🙂
As far as I understood, this process is done in the router and then enters the selected address here. It also works with a dynamic automatic assignment via DHCP.
Vielen Dank für diese informative und unterhaltsame Anleitung. Euer Blog ist definitiv ein Pflichtlektüre für Tech-Enthusiasten, und ich freue mich schon auf mehr spannende Beiträge von Zazu Berlin!
Liebe Grüße,
Andreas Zaun